如何用 ChatGPT 结合 Github 代码库问答?
弥补 ChatGPT 的「我只是一个训练数据截至 2021 年 9 月的大语言模型」短板。


短板
作为一个大语言模型,ChatGPT 的预训练数据集截至 2021 年 9 月。你如果非要查询之后的内容, ChatGPT 无能为力。甚至会给你瞎编答案。
例如 LangChain 这个非常好用的框架,和大语言模型相伴而生。LangChain 是个开源项目, 于 2022 年 10 月发布,作者是 Harrison Chase 。在《如何用 ChatGPT 和你的卡片笔记对话?开源应用 Quivr 尝试》一文中,你已经看到了它的威力 —— 目前几乎所有的单文档、多文档处理,甚至是基础的自动推理功能,背后都有它的影子。
看这星星(stars)数量,真让人羡慕啊。
因为在 2022 年推出,LangChain 显然不存在于 ChatGPT 的训练数据。如果你希望 ChatGPT 回答如何用 LangChain 给你做个博客总结工具并且部署,它首先就会告诉你「对不起,无能为力」。
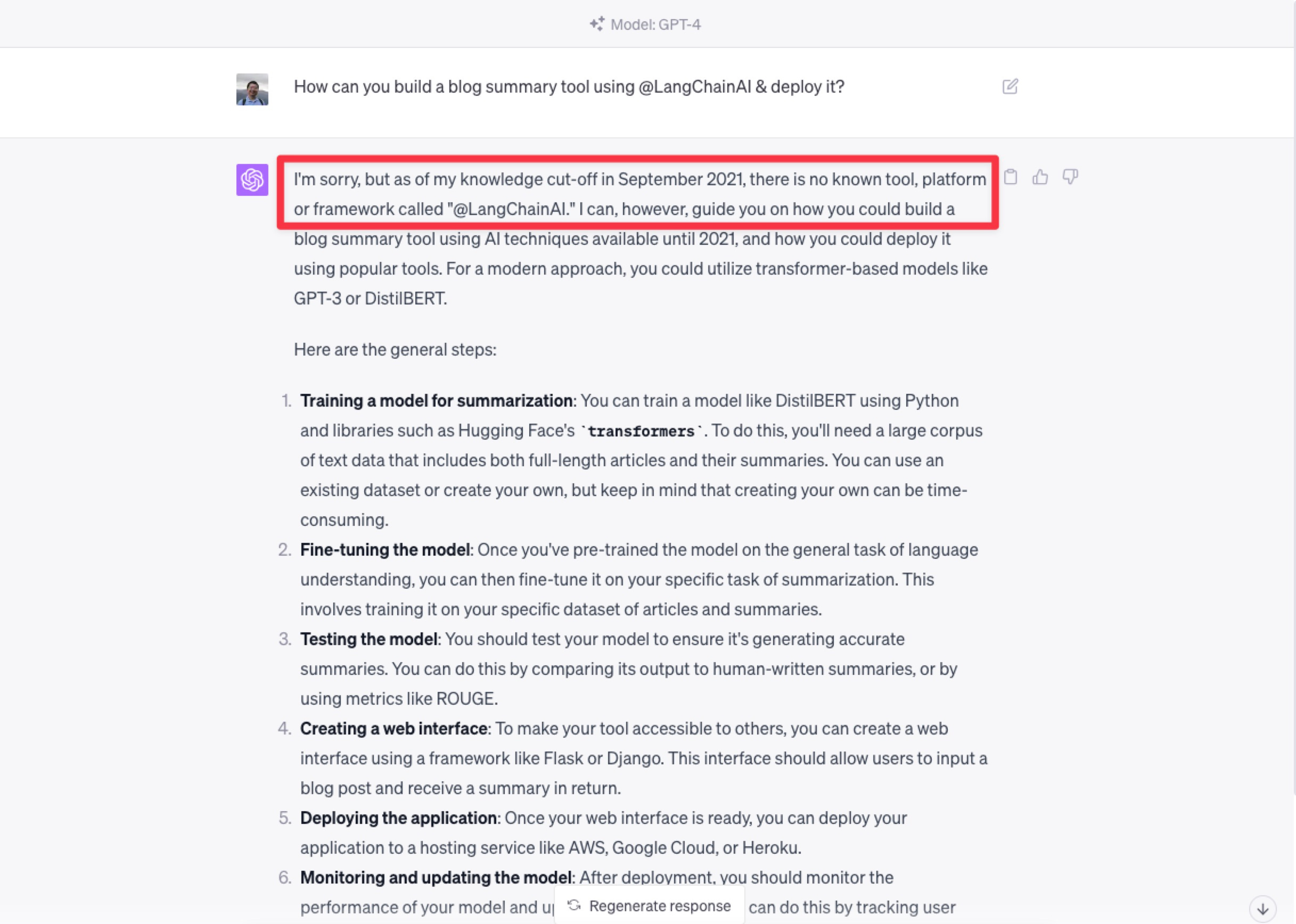
但为了避免冷场,ChatGPT 会在后面给你介绍很多总结功能模型训练和应用部署的内容。但是这显然不符合你的预期,因为你想用 LangChain 来实现。
那么有没有办法让 ChatGPT 接触到 LangChain 的资料,然后正确回答问题呢?
理论上讲,最直观的解决方法就是让 ChatGPT 联网,然后获得最新资讯。我们可以使用 Web Browsing 功能,问同样的问题。但执行的过程,似乎不大美妙。
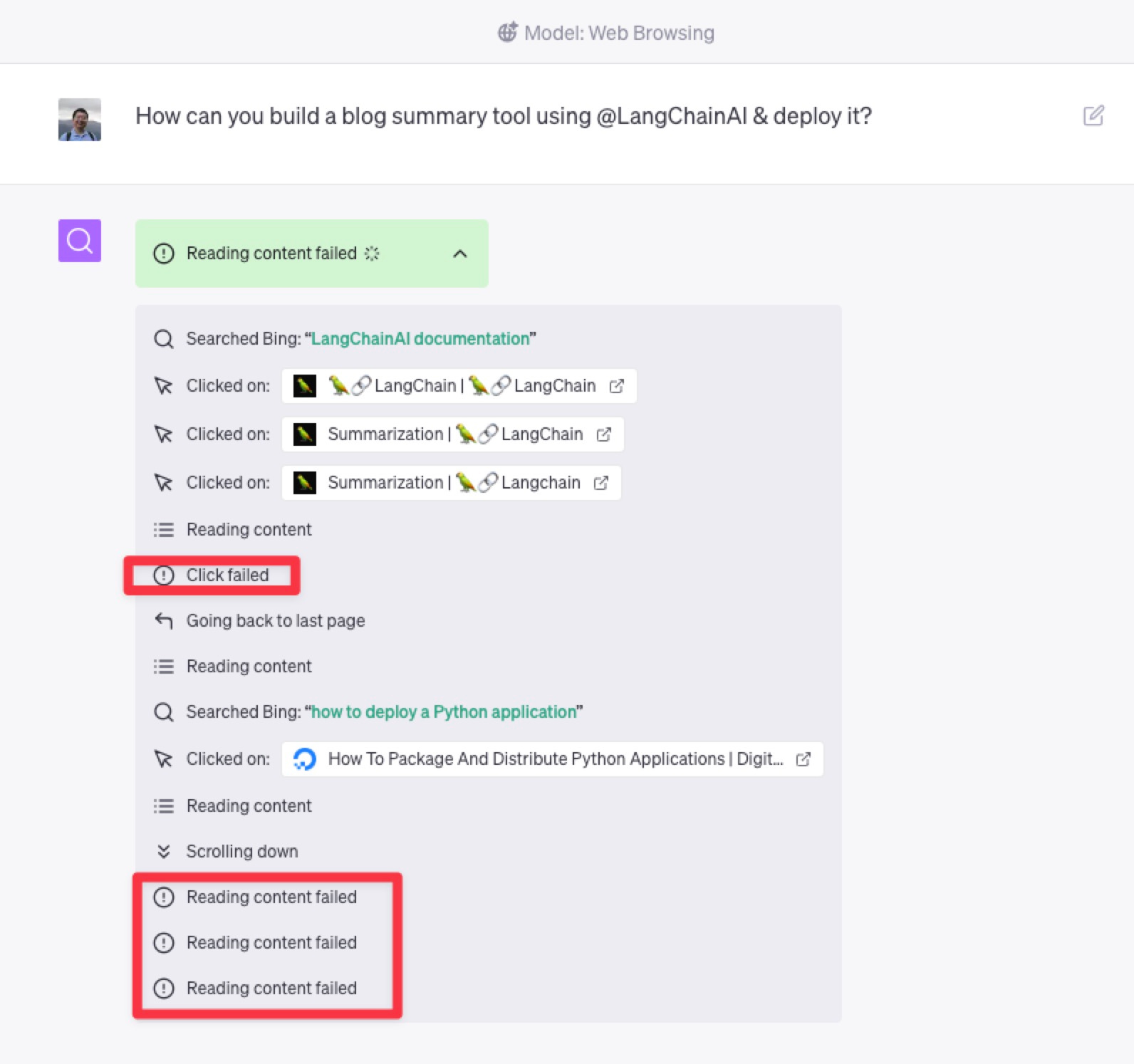
你可以看到,在检索内容的时候,ChatGPT 遭遇了一连串的失败。
这还没完,后面 ChatGPT 还在继续遭遇失败。
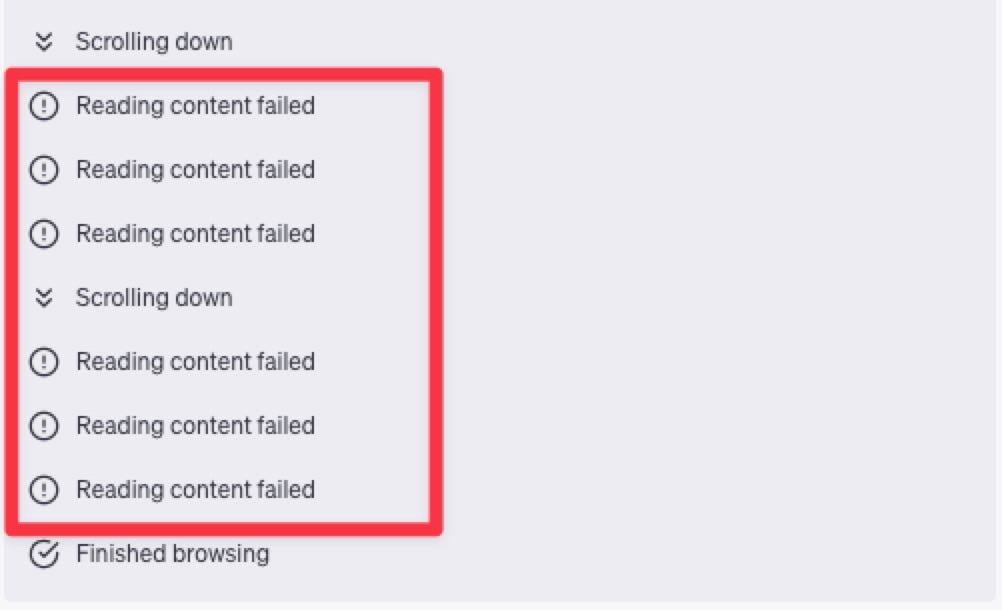
这也是 我当初使用 AutoGPT 的时候遇到的问题。虽然计划非常理想,但因为访问指定网页总是失败,最终就会导致任务卡死在那里。
不过有意思的是,一连串失败后,ChatGPT 宣布网页浏览顺利结束。看来 ChatGPT 远没有当初的 AutoGPT 那样执着,哈哈。
然后 ChatGPT 给出了回答。
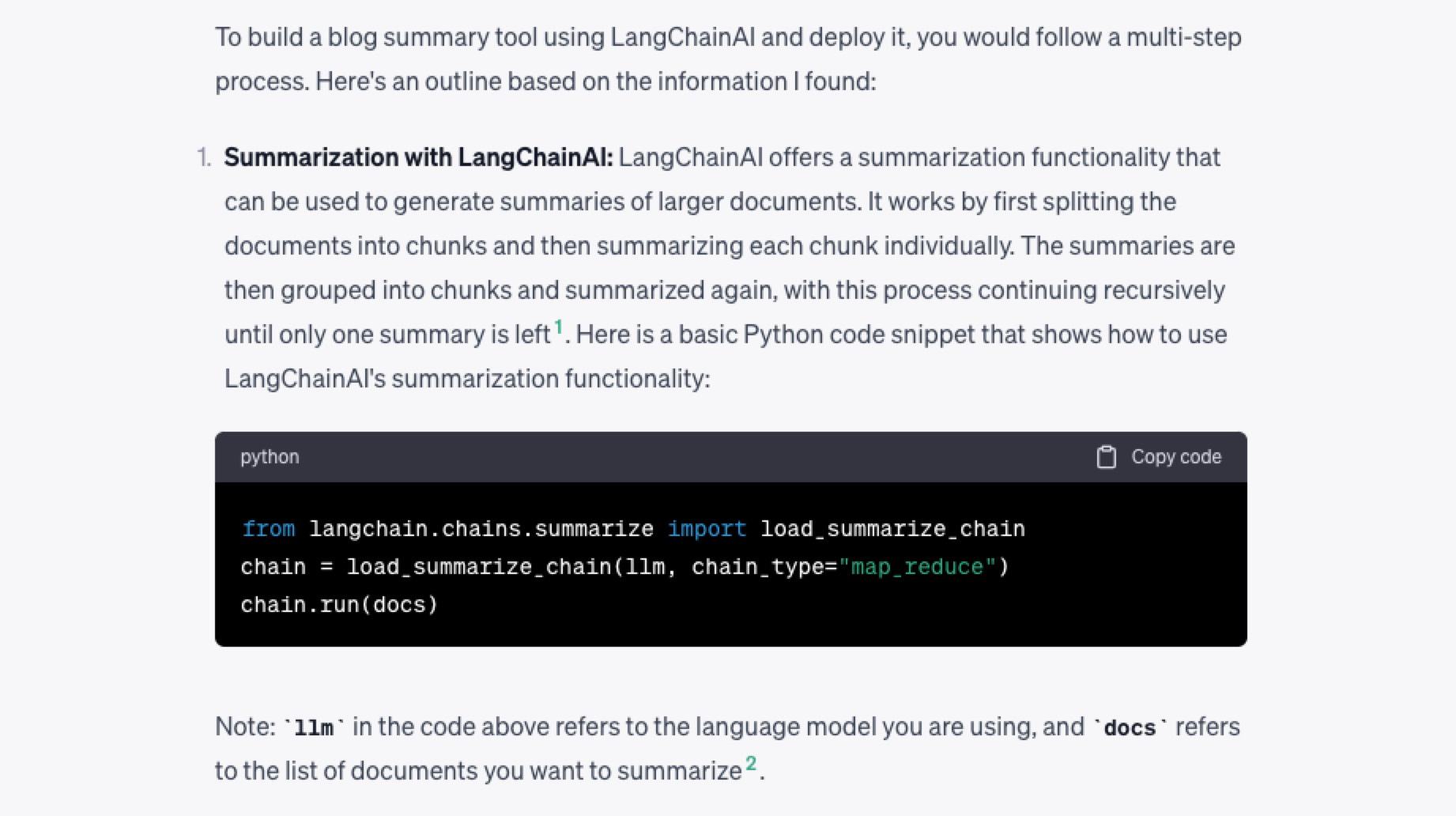
这回答看起来,也挺像模像样。可惜涉及博客总结功能的只有这点儿内容。而且,我都不用运行,就知道一定会报错。因为这里居然连基础的 OpenAI API Key 的设置步骤都没有写出来,更没有定义 llm 的选择。不定义就使用,这显然行不通。
后面应用部署的内容,ChatGPT 先给出整体架构。
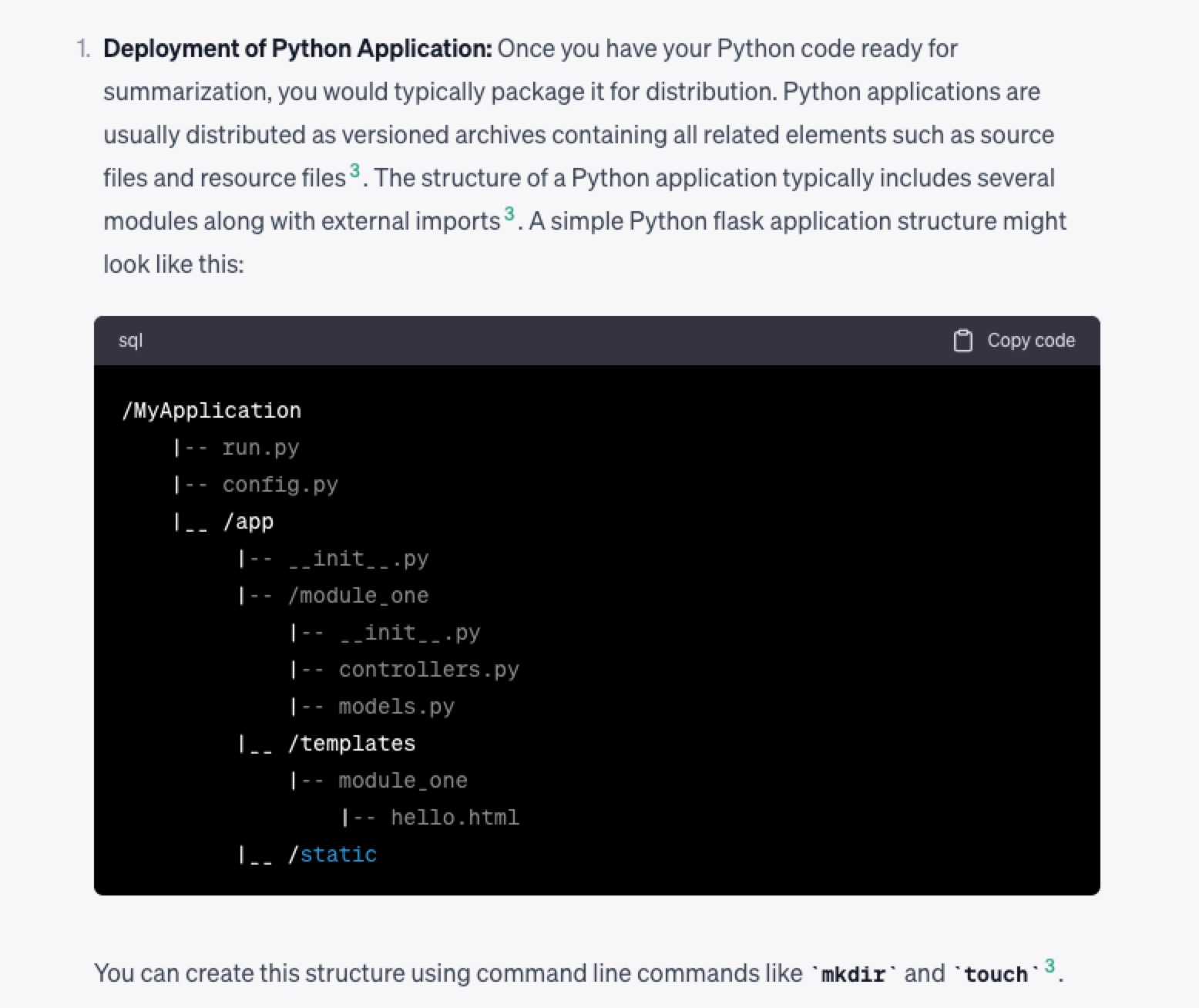
然后是具体的代码内容,包括了 run.py 和 config.py 。
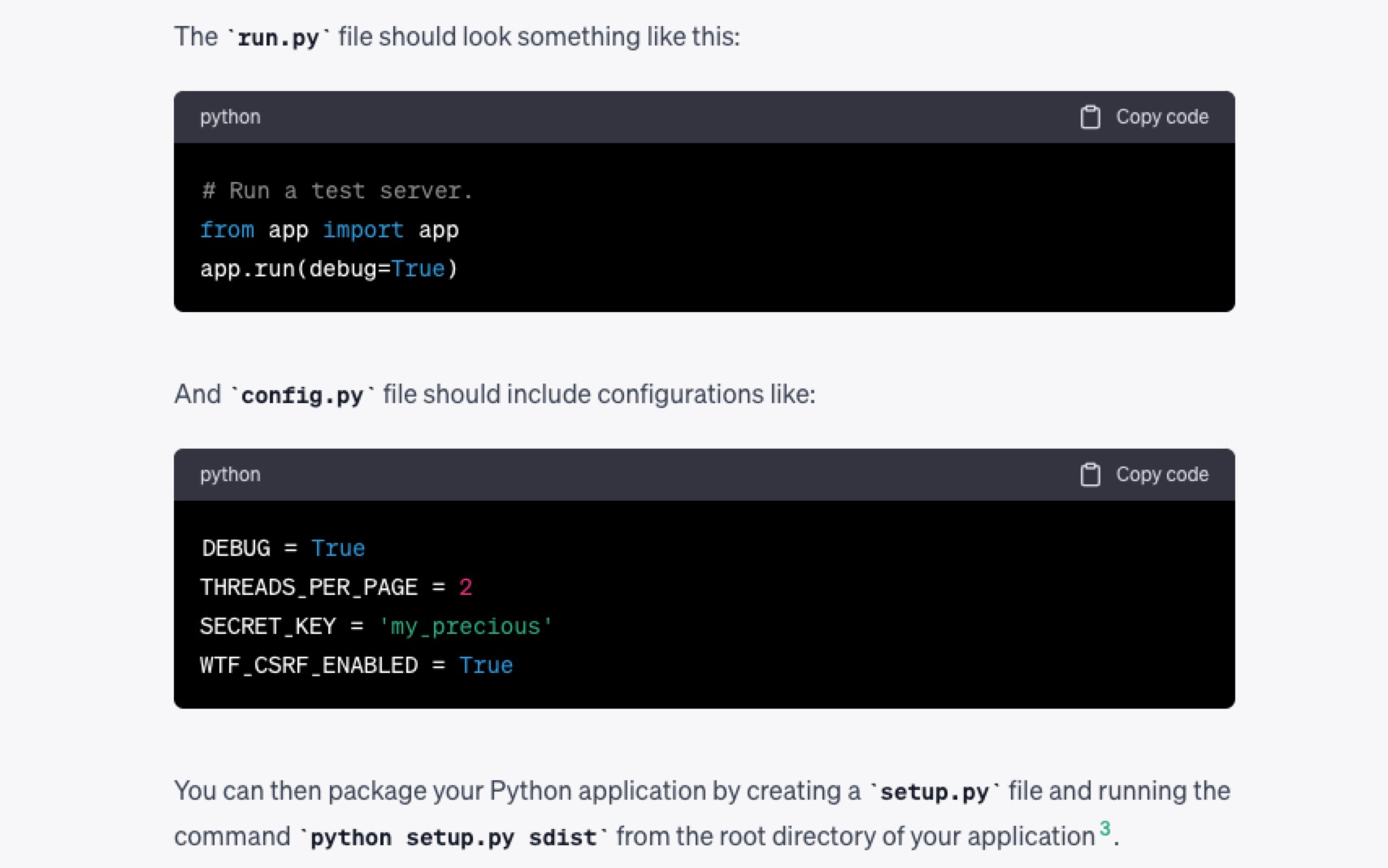
不过,这里 ChatGPT 并没有把摘要功能所在的源代码文件和 run.py 加以结合。也就是现在总结功能和应用部署之间没有任何关联。教程并不具体,你也没有办法按照其步骤来尝试使用。
ChatGPT 自己也知道理亏,所以末尾说了很多原因,表明写成这样是无奈之举。把目前给出的结果说成是「高阶教程」。
这哪里是什么高阶教程,分明就是因为获取新资料不成功导致的整体敷衍。如果 ChatGPT 在了解 LangChain 的时候,能够更加全面精准获得对应的信息,那显然结果应该更好些。
那么,这样的解决方案是否存在呢?
发现
Keep reading with a 7-day free trial
Subscribe to Shuyi’s Newsletter to keep reading this post and get 7 days of free access to the full post archives.