

Windsurf Cascade 如何为你 AI 赋能,解决真实需求?
从今天开始,就把 AI 当成你的合作伙伴,一起创造吧!


新工具
Windsurf 发布有些日子了。前几天有个黑五优惠,我还在知识星球里喊了一声。
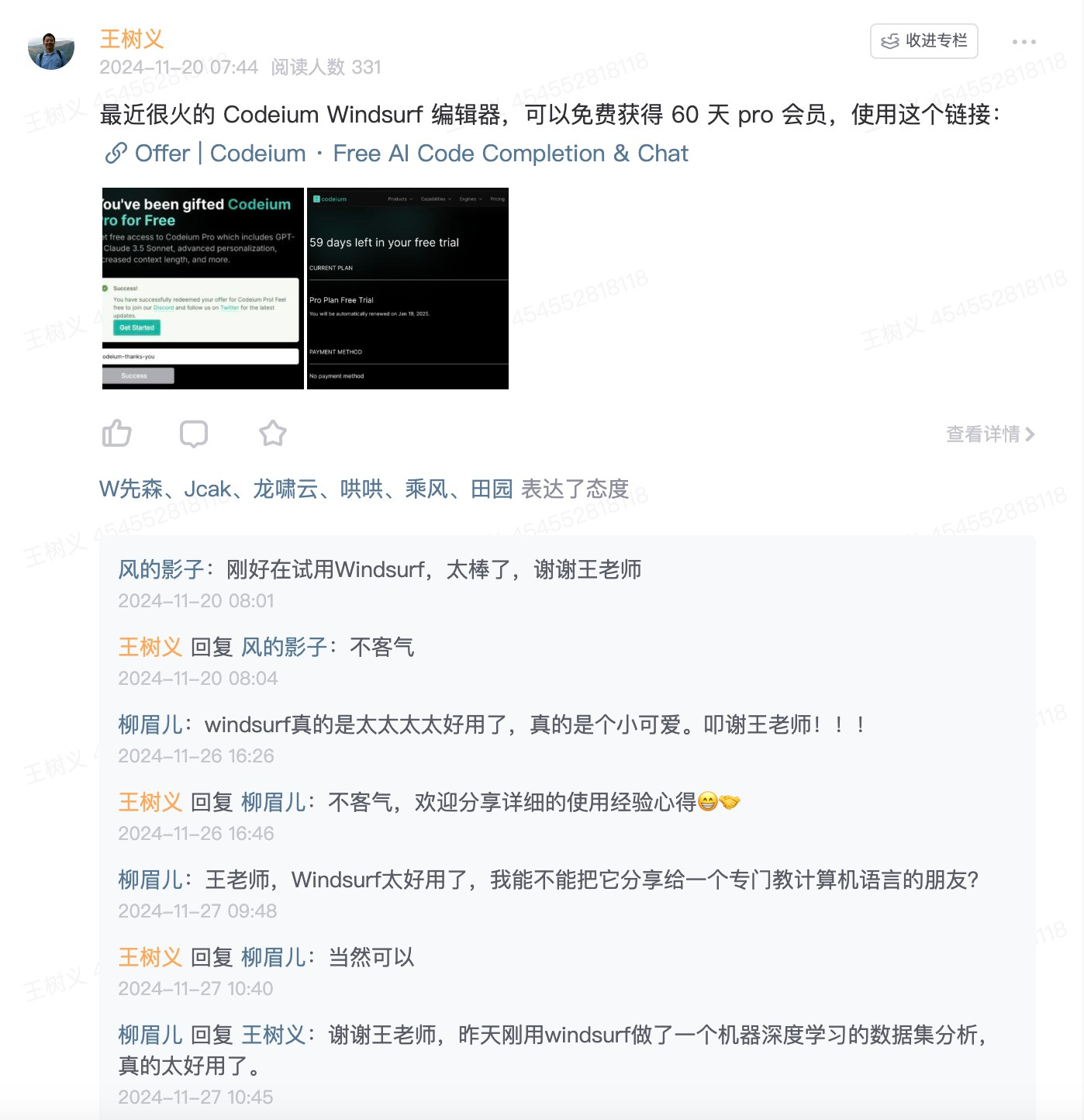
不过,兴许是羊毛被薅得太狠了,官方跑出来,宣布给大家一个试用期延长优惠,直到 12 月 11 号。
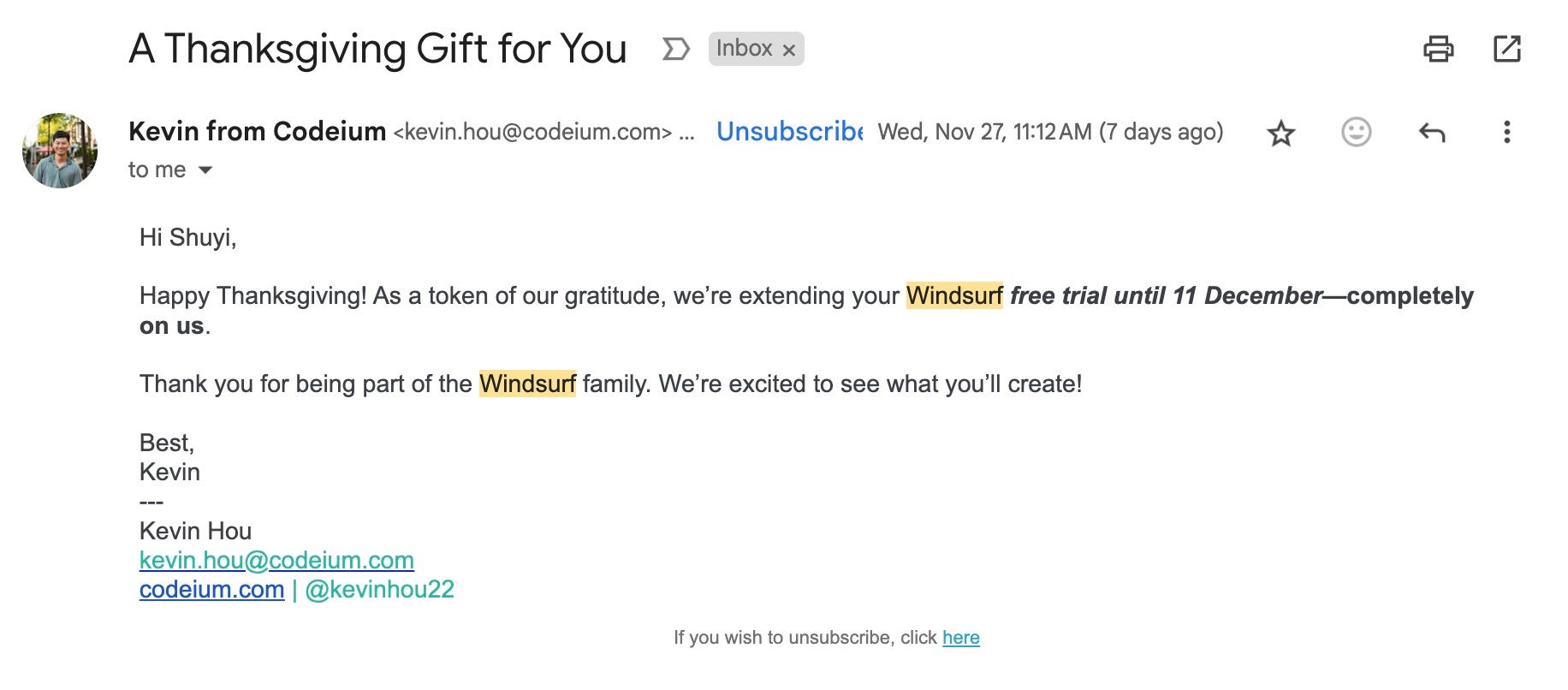
相比起原本的两个月,这个免费试用时间其实是大幅缩短的。咱那个 pro 账号 11 日之后究竟还能不能用,现在是个未知数。
很多小伙伴开始用 windsurf,总是感觉很兴奋。知识星球上,有星友用它开发了 Todoist 和 Obsidian 链接插件。

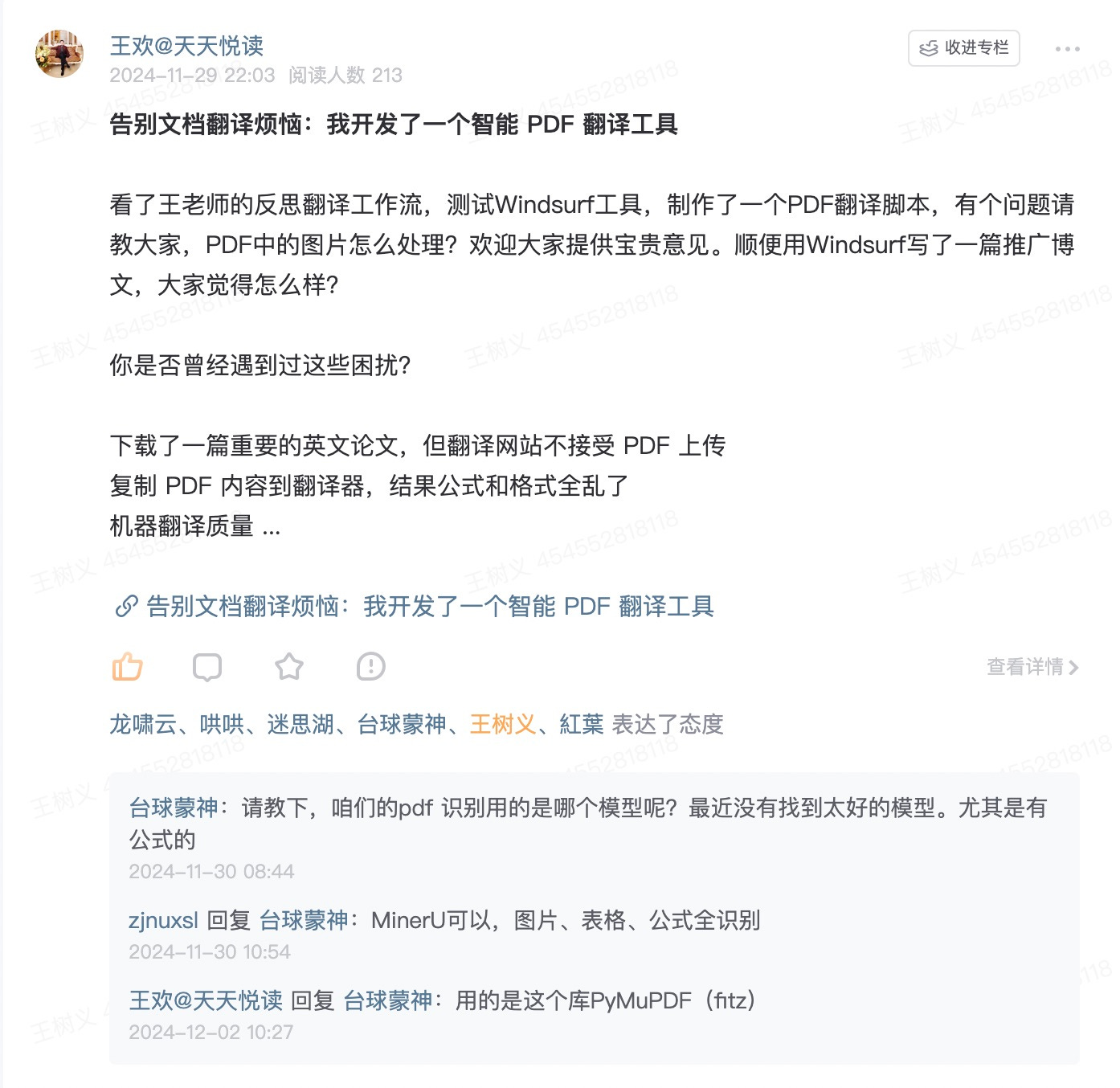
有的星友则更进一步,做了个智能 PDF 翻译应用出来。
看见别人玩儿得那么嗨,估计你也跃跃欲试。但是很多小伙伴还是没能掌握 Windsurf ,尤其是它特色的 Windsurf Cascade 的妙处。
如果你看各种介绍,会了解到一些定义。
例如 「Cascade 是一个强大的推理引擎,能够进行深度的多步骤思考,具备编辑和解释代码的能力」,再比如「Cascade 具备实时感知开发者行为的能力,能够基于持续的工作内容执行、调整和继续编辑任务」。
但这究竟是什么意思?
咱们今天,就用一个实际的例子,说明 Windsurf Cascade 上述能力。让你也能用它快速开发原型系统,满足自己的实际需求。
例子
这个例子从网上一个现成的 API 作为起点,根据咱们的需求进行调整,生成一个咱们自己的软件包,并且让全世界都可以下载安装。这还不算,咱们还要在本地弄一个 Web 界面来方便用户来使用。
听起来,是不是好难啊?
一点儿都不难。
首先 ,咱们先来看一看这个 API。
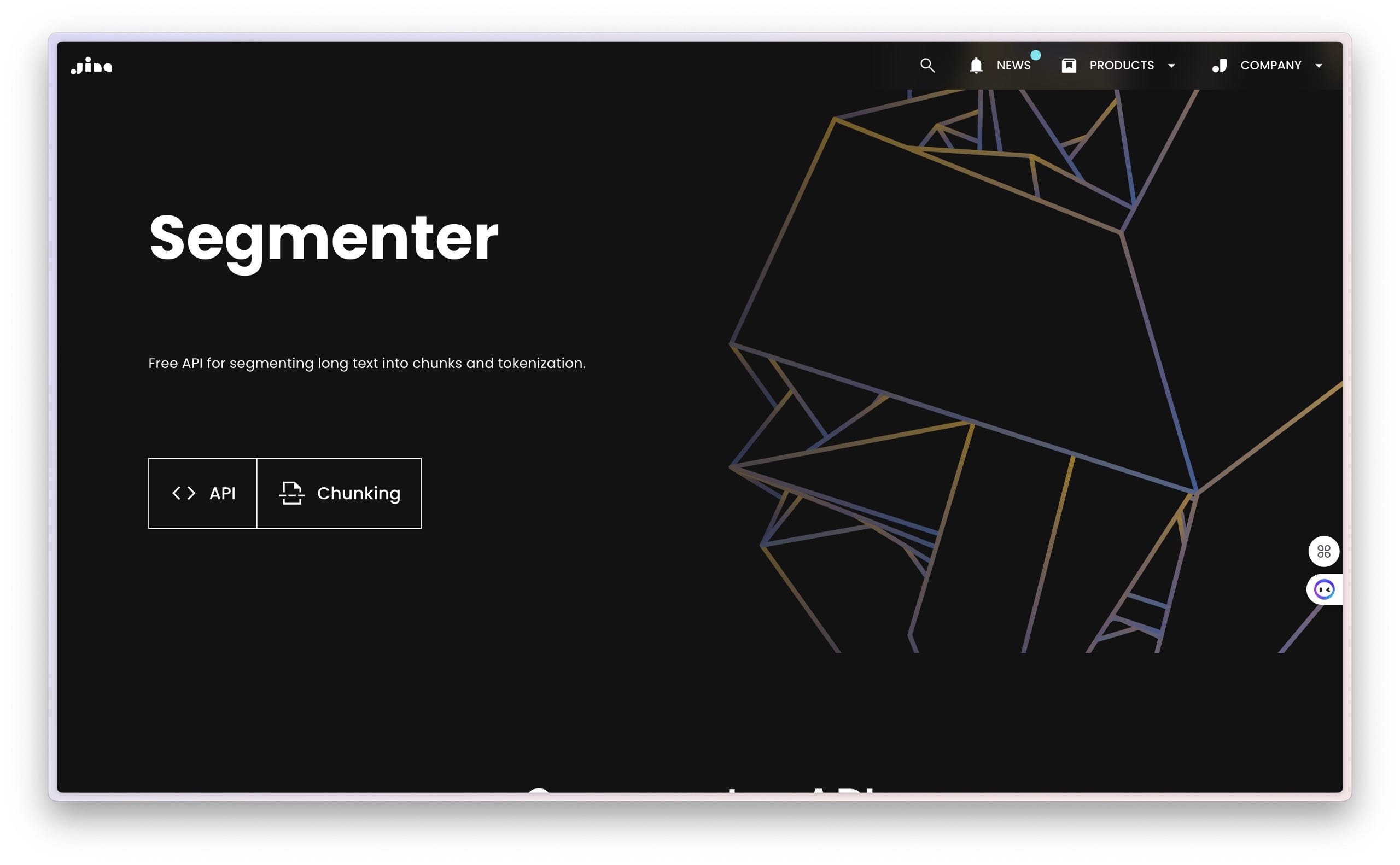
这个 API 来自于 Jina AI ,作用是可以帮你给长文本分片。
估计你还记得,我那个 Python的AI工作流框架中的一个重要功能是长文本分片。 因为大语言模型有个上下文限制,超出这个窗口,就无法处理。在Openrouter的模型列表左侧,你可以清楚看见 Context Length 这一项。从 4K 到 1M ,跨度很大。
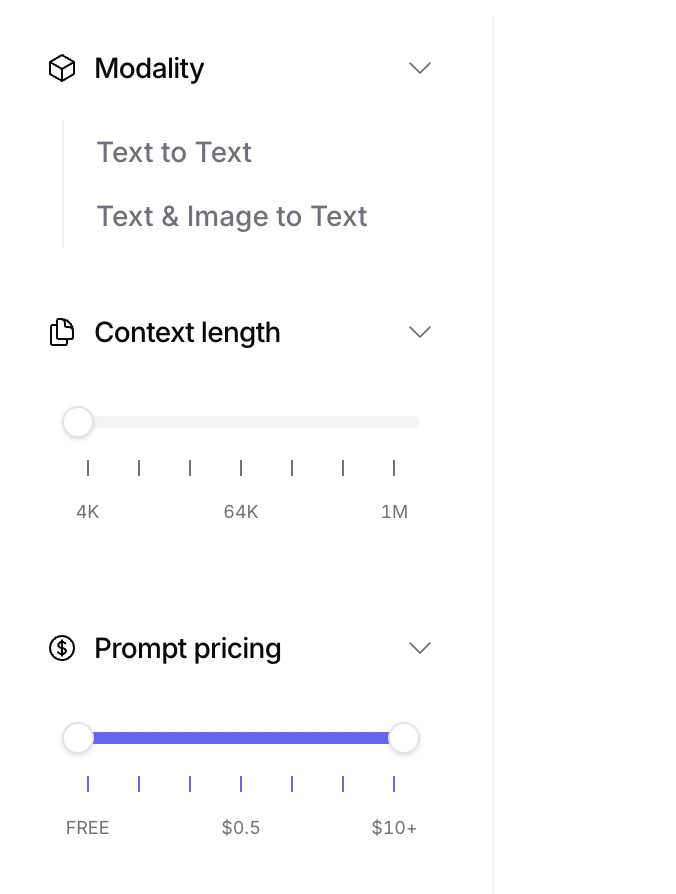
另外,即便你的模型可以支持很长的上下文窗口,如果你不限制分片长度,很有可能模型输出的时候会自作主张,帮你「精简」输出长度。对于长文写作和翻译来说,这是很糟糕的。因为很多细节会被忽略掉。
我之前在 Python 框架里面,用的是 Langchain 的 RecursiveCharacterTextSplitter 作为基础来操作。
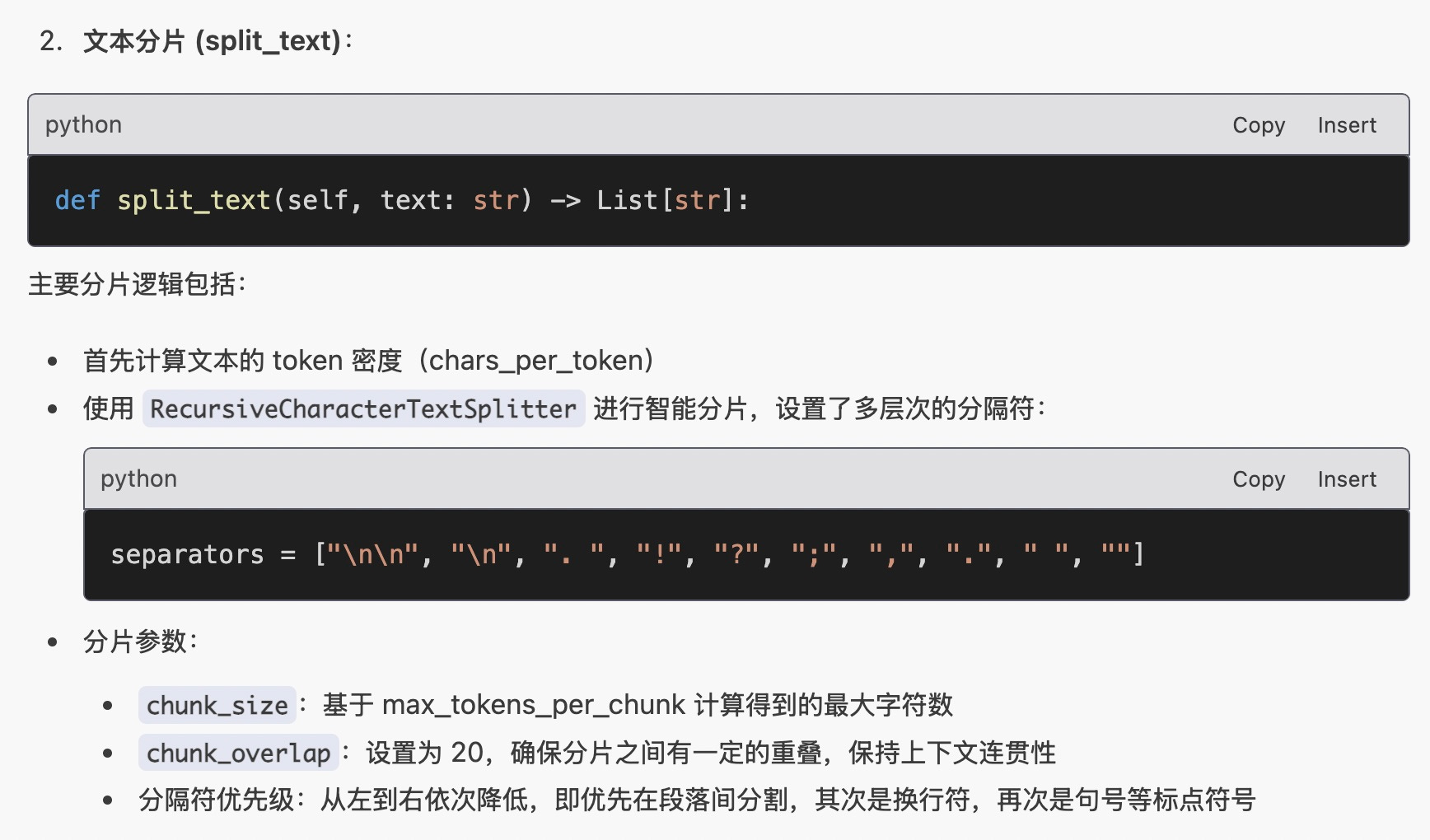
当然了,你看到的这个解释,也是 Windsurf 分析了代码库之后自动给出的。
但是,我对 Langchain 的这种分片方式,并不满意。边缘处出现的 overlap ,总会带来意想不到的问题,例如标题甚至标题后的一句话,都出现两遍。如果不人工检查,很容易让这些纰漏出现在最终结果中。
那你说,咱们把 overlap 设置为 0,让两个分片之间,没有任何重叠,不就好了?
唉,每当你看到一个问题明晃晃摆在那里,应该多思考一步 —— 这是不是人家的「解决方案」呢?
如果你设置 overlap 为 0,有的时候当标点符号缺失时,一句话可能被从中间截断,导致问题更加严重。
既然原先的拆分方式有问题,当我看到 Jina AI 出的这个 segmenter API 的时候,还是很愿意试试看的。
我在官网上试了中英文长文的分片效果,其实都不错。

中文用的还是古文。
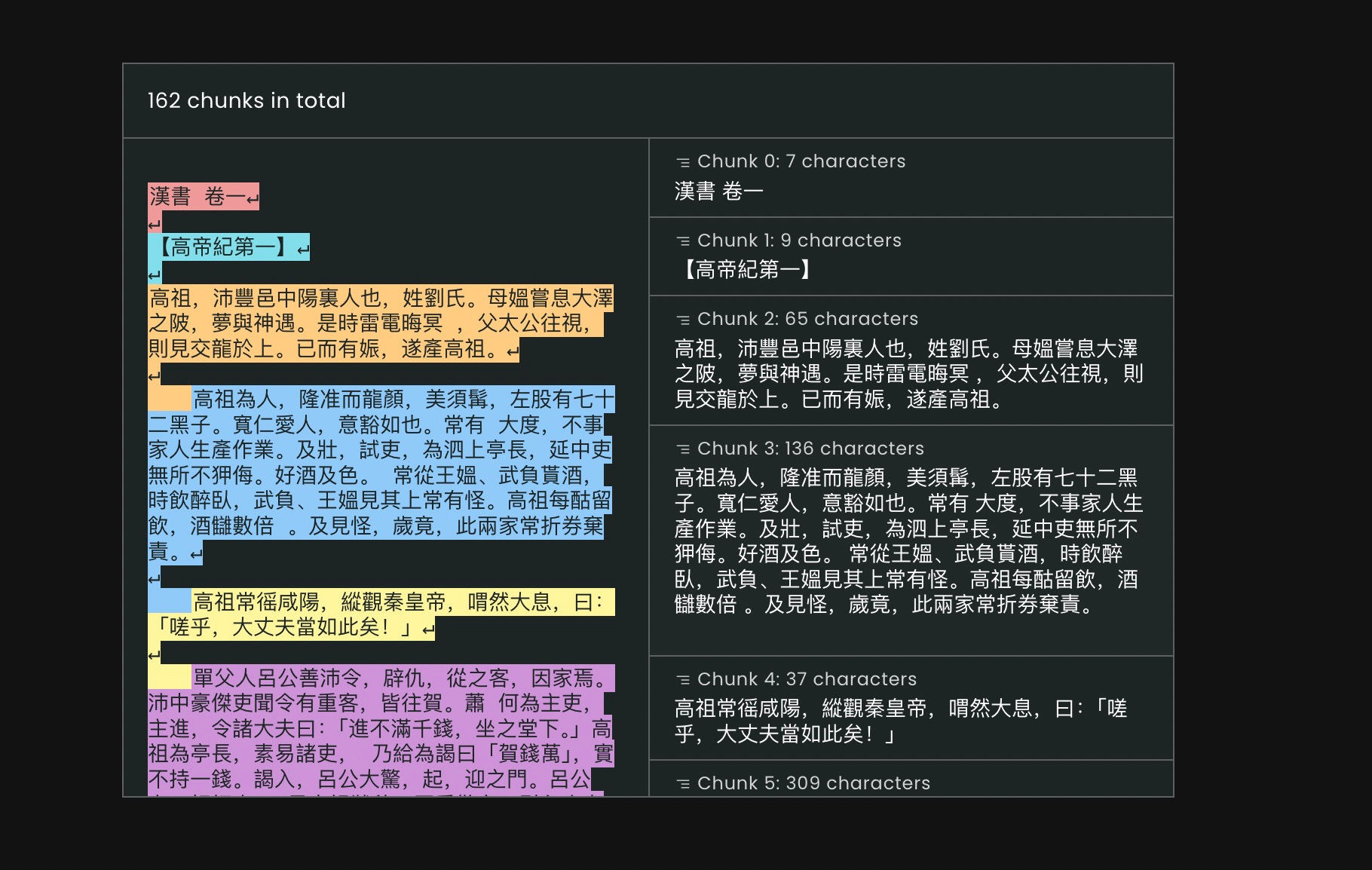
只不过,看到这里你应该也能发现 —— 这个工具分段,好是好,可是不是过于稀疏了?
原本,我们是希望每一段不超过一定的 token 数量(例如这里设定的是 1000). 结果,分拆的结果居然是一行一段,一句一段。很多段的字符数是个位数。
这就有点儿「过犹不及」了 —— 一篇文章拆成 3-4 部分交给工作流,和拆成 30-40 部分,运行效率显然差很远。毕竟每一次调用模型,都会因为提示词和上下文增加额外开销啊。这样不仅处理速度变慢,也会造成更长的账单。我受得了,我的钱包受不了啊。
怎么办呢?我于是决定,Windsurf Cascade ,你上吧。
Keep reading with a 7-day free trial
Subscribe to Shuyi’s Newsletter to keep reading this post and get 7 days of free access to the full post archives.