字幕还要自己改?我做了个 Skill 让 AI 自己全干了
将这种迭代循环纳入到工作流中,可能给你后续工作带来显著的「复利」改善


刚需
昨天我翻了一下我公开发布的视频的索引,发现仅在 B 站上,就已经接近 350 个了。

不过其中加了字幕的,占比不多。
因为啥?我懒啊。
早先,加字幕得手动弄。一个长视频下来,时间花得比录课还多。那时候自不必说了,甭管观众如何呼吁,我是不为所动的。
后来有了 AI,按说这活儿应该简单了。专业工具(例如立青的 BibiGPT 或剪映)识别准确率确实不低,出来的字大部分都对。但是不行,总有那么一些错误明晃晃摆在那里,必须得整体过一遍才能发现。这导致后续手工调整依然非常繁琐。所以很多视频,我依然选择不加字幕,避免这些错误贻笑大方;或者被观众呼吁得烦了,则干脆 AI 直出字幕,您凑合看吧。
最近参加教创赛,需要给长视频加字幕,而且对质量要求很高。我于是想:能否让 AI 出字幕的时候,自动处理常见问题,端到端高质量输出?甚至还能把我原先不曾做过的章节分割 —— 就是你在 B 站某些视频里看到的底 / 顶部进度条 —— 也自动烧录进去?
想法有了,刚需驱动,于是我就动手做了一个 Skill,专门处理视频字幕和章节进度条等问题。这算是教创赛视频制作的副产品。没想到,这个过程里,我收获了很多东西。
比如 6 月 5 日,我给自己的新书《AI 高质量论文写作法》做宣传视频。出版社的营销编辑建议我把字幕给加上。出于路径依赖,我还是先试了剪映的自动字幕。识别的倒是挺快,不过稍一检查就发现,哪怕这短短几分钟的视频里也净是错,例如:我自己的名字「王树义」认错了,写成了「王书一」,字幕里的 AI 全成了小写的 ai,「玉树芝兰」写成了树枝的「枝」—— 这些都得我亲手去改。
我叹了口气,换用这个 Skill 重新处理同一个视频,这类问题它自己就抓出来修对了。成品我从头过了一遍,竟然一处要改的都没找到。

今天咱们就来分享一下我制作这个 Skill 中积累的经验,在文章末尾,我也会把这个 Skill 的完整内容一并分享给你。
在讲怎么解决之前,我想先聊一个问题 —— 字幕的毛病,到底出在哪?
痛点
你可能觉得,字幕的问题不就是识别不准嘛,错别字呗。说实话,我以前也是这么想的。直到我做教创赛录课视频字幕添加,带着团队小伙伴一次次检查手工调整字幕,一次次被折磨,我才意识到事情没那么简单。
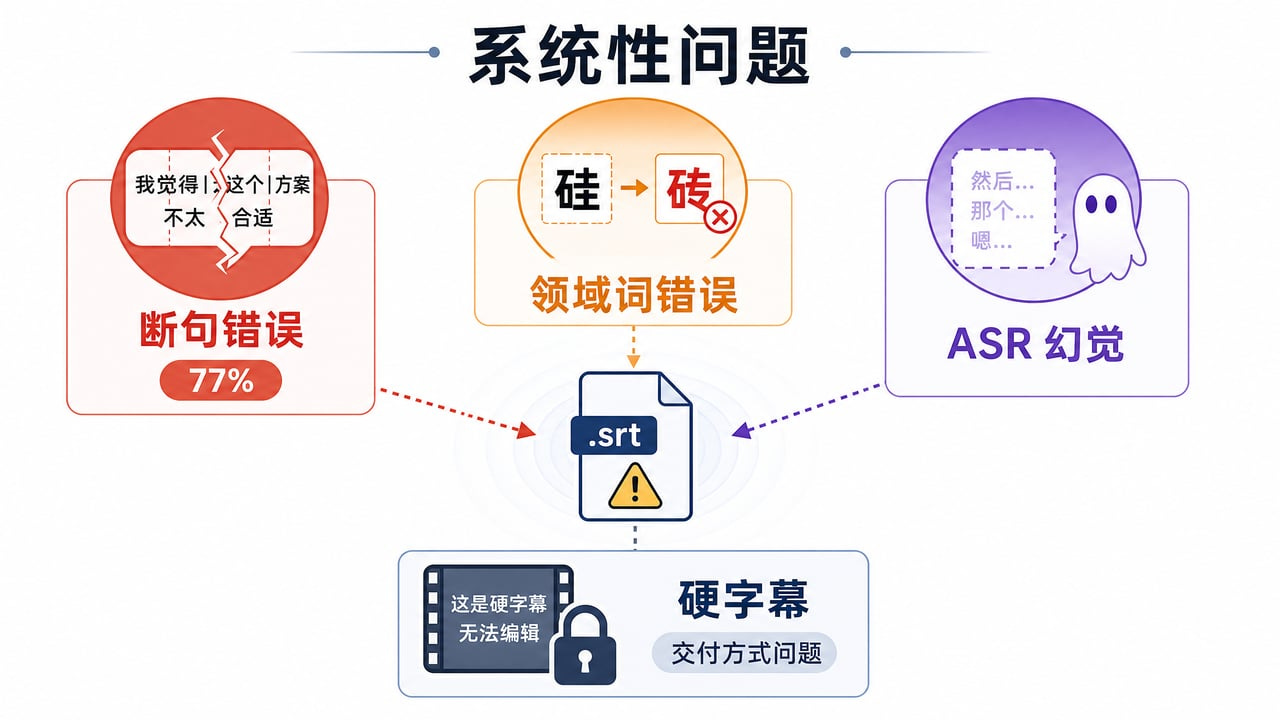
第一个问题,也是最烦人的:断句碎。
自动字幕按什么断句?主要是按音频里的停顿和静音。问题是,讲课的人说话不是播音员,中间会换气、会停顿、会重复连接词。结果就是 —— 一条字幕在半句话的地方被拦腰截断。
你想象一下这个画面:你正在讲「我们在使用大语言模型的时候」,说到「大语言」三个字,换了口气,字幕就在「大语言」后面断开了。下一句从「模型的时候」开始。读者看到的是什么?一条「我们在使用大语言」,一条「模型的时候」。每个字都对,但观众看起来完全不是那么回事。

如果说这些常见词汇中间被断开的时候,观众还可以凭借着对常识的理解自动脑补,那更要命的是专业词语被中间断裂。「信息管理系统」,在「信息」后面断开;「机器学习」,在「机器」后面断开。字都没错,但语义全碎了。你读着这些断成残片的字幕,得自己在脑子里拼回去 —— 这比没有字幕还累。特别是对于一些专业入门初学者来说,可能听得一头雾水

第二个问题:专有名词系统性翻车。
这个更隐蔽,也更让人头疼。通用的语音识别模型没见过你那个领域的词,它就按发音硬猜:Trae 变成 Tray,Claude 变成 Cloud,「汶上县」听成「上线」,「鲁棒」变「鲁邦」。这些错误有个共同特点:发音上完全合理,语义上基本离谱。你通读校对的时候,如果不熟悉这些词,根本看不出来——因为它们读着「顺」,但意思全错了。
还有几个问题,虽然不像前两个那么扎眼,但也让人头疼:静音段冒出「请不吝点赞、订阅、转发」这种 AI 脑补出来的话 —— 这是语音识别的幻觉,行话叫 ASR 幻觉,ASR 就是自动语音识别;识别结果里混入「這」「門」「課」等繁体字,肉眼极难发现 —— 这是简繁混杂。
你看,字幕的问题,远不只是「错别字」那么简单。
那到底哪个才是主要矛盾?我以前凭直觉,觉得错字最多 —— 毕竟改的时候,满眼都是红笔圈出来的错别字嘛。
直到我做了一次量化复盘。
做法不复杂:把 AI 自动生成的字幕,和我自己逐条手工精调之后的版本做 diff—— 就是逐条对比两个版本的差异,然后把每一处修改分类 —— 你改的是断句,还是错字,还是别的什么?
结果让我吃了一惊:大约 77% 的人工修改是断句问题,只有约 13% 是错字。(以文本被改动的字幕条为单位,两个视频合计四百多处修改。样本谈不上大,但方向足够清晰。)

换句话说,我花大力气在校对错别字,但真正让我头疼的、占了大头的问题,是断句。
还有一个容易被忽视的交付方式问题:很多工具默认把字幕烧录进画面,但创作者经常并不想要硬字幕——平台有自己的字幕轨,烧录后无法回退,不利于多平台分发。字幕应该是可分发的资产,而不是焊死在视频里的零件。
出路
问题重新定义了,解法也就不一样了。
我做的这个 Skill,叫 video-subtitler。说「做」,其实更像当导演:问题怎么定义、方案怎么取舍、质量怎么验收,这些是我的活儿;代码是我指挥 Claude Code 写的 —— 它写,我挑毛病,它再改。这个 Skill 不是在「识别 + 校对」的老路上修修补补,而是围绕「修对的东西」重新设计了整条流水线。核心思路有三层。
先说专有名词怎么治:三个独立证据源互相校验。
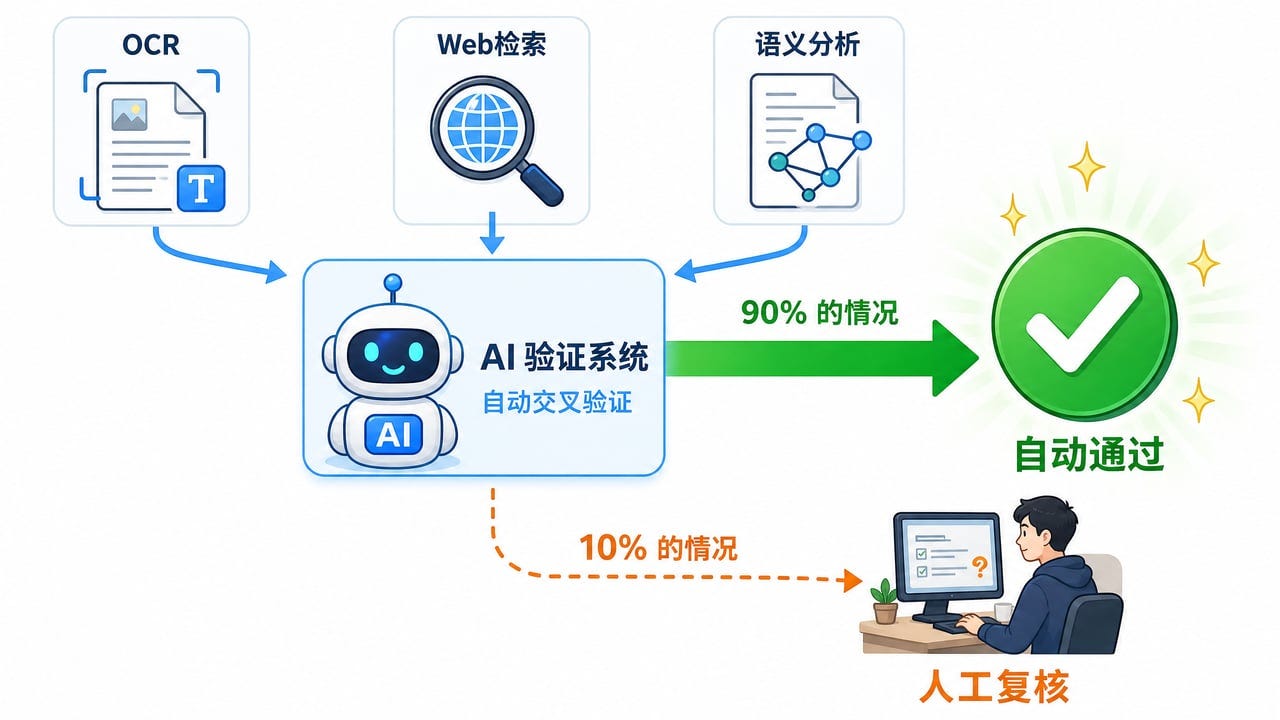
不是靠人眼通读,而是让三个独立的证据源交叉验证:幻灯片 OCR—— 把画面里的文字识别出来 —— 提供屏幕上实际写着的专有名词和数字,Web 检索逐个核实人名地名,上下文语义逐条复查同音字。三个来源对上了,才算过关。打个比方,这就像三个互不串供的证人,分别从不同角度指认同一个人 —— 比一个人反复看十遍可靠得多。
光修得对还不够,还得验得住:LLM 做菜,脚本验收。
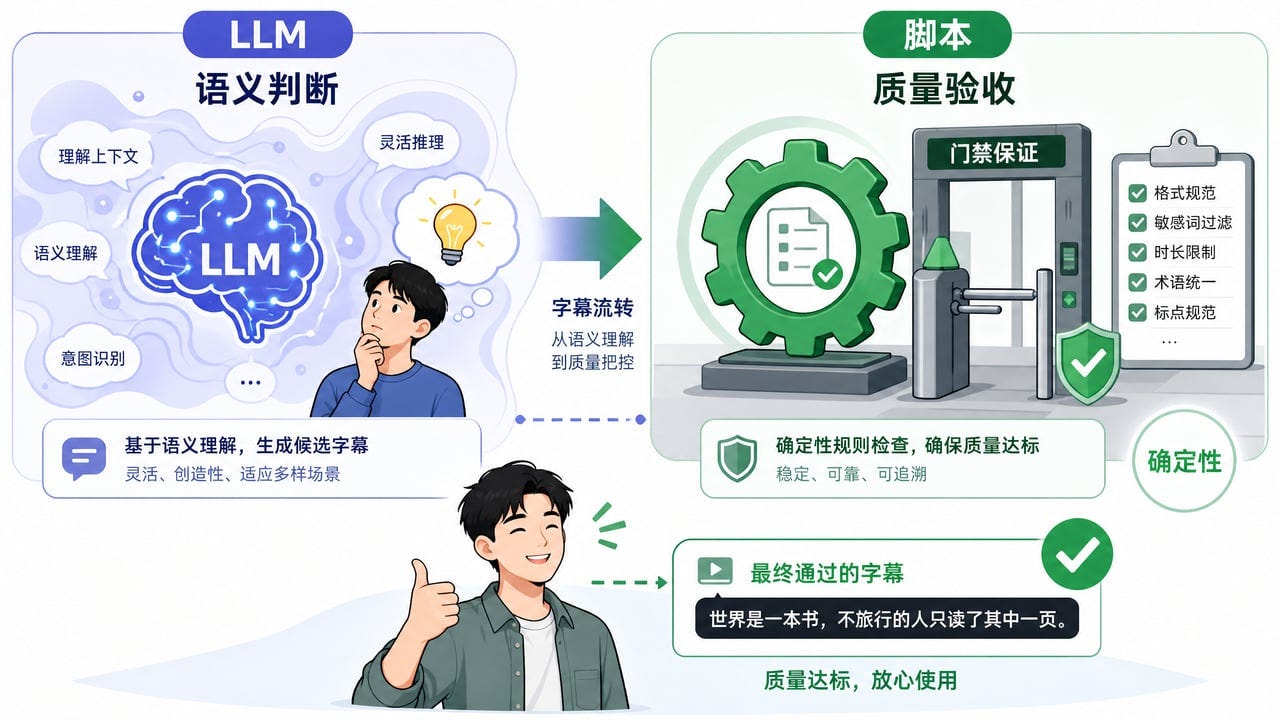
LLM 就是大语言模型,语义判断交给它;质量验收交给脚本 —— 脚本是死的,同样的字幕给它,每次都按同一把尺子量,这种「每次结果都一样」的可靠,行话叫确定性。它把每一条字幕都查一遍,不是抽几条看看,不合格不放行。为什么这么分?因为语义判断和验收是两件不同的事 —— 判断需要理解力,验收需要确定性。
最后是你拿到手的东西:默认轻交付。 默认交付 SRT 字幕文件——一种通用的字幕文本格式,哪个平台都认——加逐字稿,而不是直接把字幕焊进视频。你拿到一个焊死的视频,和拿到一个可以随时改的字幕文件,感受完全不同。烧录是可选项,你明确要求了才做。
验证
思路归思路,效果怎么样?
最核心的变化在断句——普通流程主要按静音间隙断,半句截断是常态;这个 Skill 不按静音断,而是理解语义后再切。修的就是那个占 77% 的问题。这个问题修对了,字幕的「读着累」就从根本上缓解了。
然后是专有名词 —— 普通流程靠校对者凭感觉抓;这个 Skill 用三源交叉验证,OCR、Web 检索、上下文语义,三个来源对上了才算过关。领域词也不用每个视频从零开始,验证一次,后续视频自动复用。
其余的,质量验收从人眼通读,变成脚本逐条把关 —— 像安检口,每条字幕都得过这道门禁,不合格就拦下;交付从默认烧死变成默认 SRT 加逐字稿;章节从手敲时间戳变成自动生成章节文件,B 站、YouTube 各一份,格式都对好了 —— 每一项都是把「凭运气」变成「有保障」。
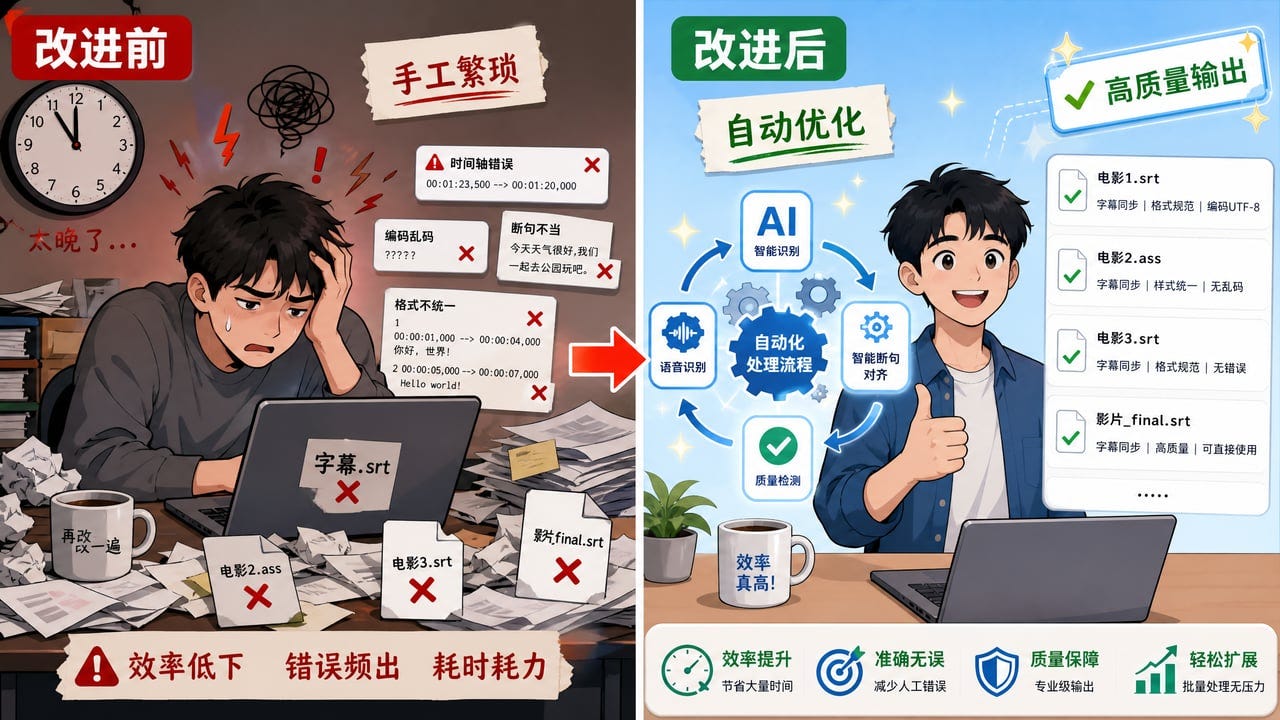
回到开头那个例子。6 月 5 日的新书视频,剪映连我的名字都认错;这个 Skill 处理同一个视频时,语音识别一样把「王树义」听成了「王书一」—— 但画面里明明白白写着「王树义」,OCR 一比对就现了形,它自己改了过来。

「玉树芝兰」靠 Web 检索核实,连两本书名该加的书名号都补上了。等成品到我手上,从头过一遍,一处要改的都没找到。一个视频的样本当然说明不了一切,但不是我眼神不好,而是修对了东西,问题就真的少了。
效果有了。下面我来跟你聊聊,我踩坑之后获得的一些经验教训。
Keep reading with a 7-day free trial
Subscribe to Shuyi’s Newsletter to keep reading this post and get 7 days of free access to the full post archives.