Perplexity 的 Deep Research 功能,好用吗?
它会不会是 OpenAI Deep Research 的强悍平替呢?


兴奋
昨天晚上,我在刷社交媒体的时候,看到有些用户已经可以用上 Perplexity 的 "Deep Research" 模式了。我猜这功能应该是逐步开放的,就赶紧打开自己的 Perplexity 看了看,结果还没有这个新模式。当时心里还真有点小失落。
Perplexity 官方宣称,这个「深度研究」模式生成的结果非常厉害,仅次于 OpenAI 的 Deep Research。
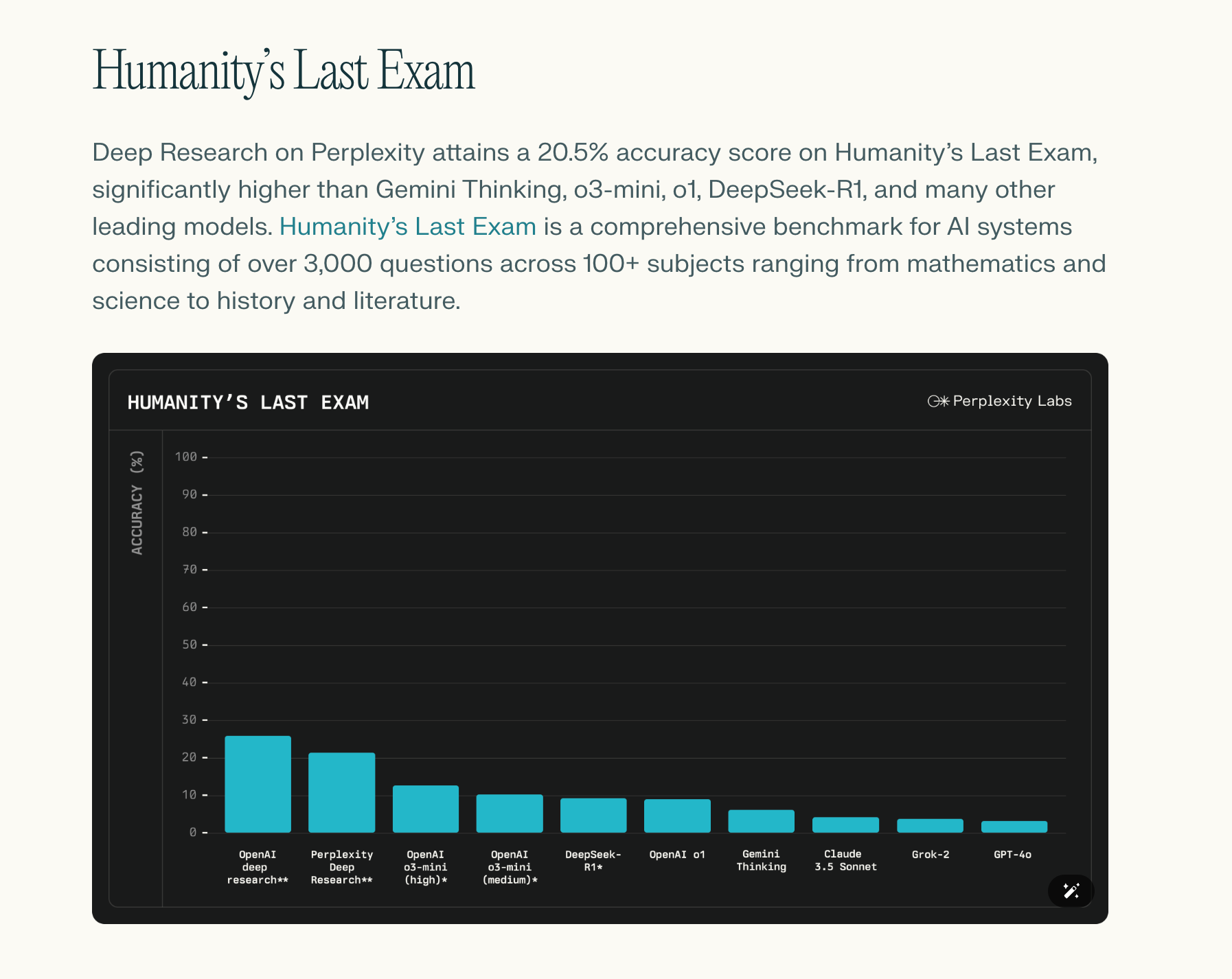
虽然性能上排第二,但对咱们大多数人来说,Perplexity 这新功能太有吸引力了。为什么?关键在于价格差异啊。

不交钱的用户,每天还能免费用 Perplexity Deep Research 几次;如果你愿意付费(每月 20 美金),那就能每天不限次数地使用了。
你可能也知道,要想高频率使用 OpenAI 的 Deep Research 功能,现在得订阅 OpenAI Pro 账号 —— 每个月 200 美金,这可不是一笔小数目。
不过,几家深度研究应用统一命名,这也挺有趣的。我看到赵赛坡先生转发的这张图,真是乐不可支。

现在至少有三家大模型应用提供商都用了相同的名词(深度研究)来描述这个功能。确实有点 「泛滥」 了。但对咱们普通用户来说,这意味着更多选择嘛,而且说不定很快就会有压力,迫使某些服务订阅费用下降,或者在相同价格下提供更多功能。这难道不是好事吗?
今天早上我一睁眼,惊喜地发现我的 Perplexity 已经支持 Deep Research 新模式了。
我特别开心,马上就在知识星球「玉树芝兰」里跟大家分享了这个好消息。有位星友立刻建议我赶紧测试一下。
下面,我就来和你分享一下,我的测试过程和结果。
测试
我测试的题目是这样的:
deepseek R1 模型的创新之处有哪些?有什么实际应用场景?调研的时候使用的资料优先级为:先英文后中文;先同行评议学术论文,后其他网络来源。用大一新生能听懂的语言来讲述,越细致越好。
你看,这其实是我最近在折腾 DeepSeek 不同 API 来源和搜索功能时,总结出的一套提示词。我的目的是找到高质量的信息来源,因为只有这样才能避免 「garbage in, garbage out」(垃圾进,垃圾出) 的结果,对吧?
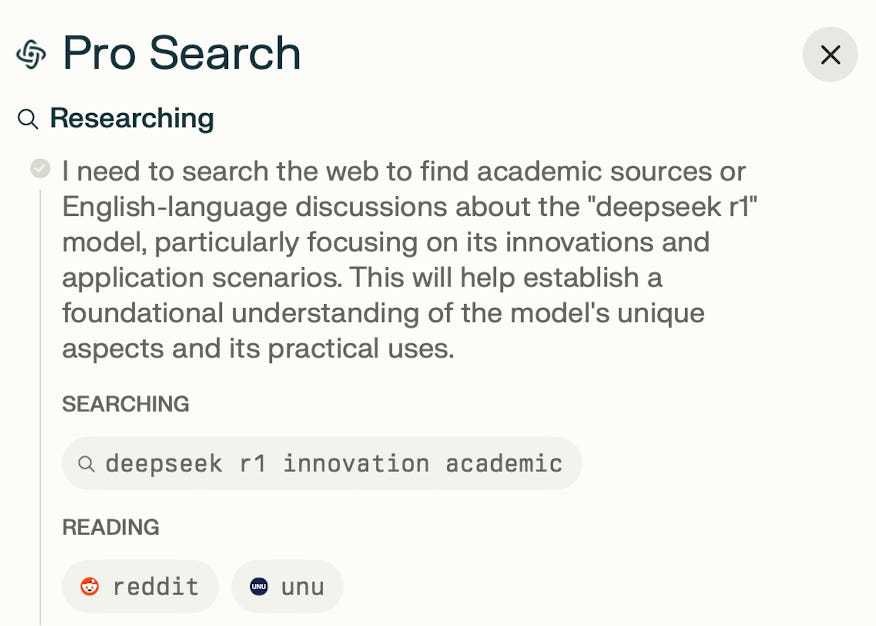
Perplexity Deep Research 模式开始工作了。
Keep reading with a 7-day free trial
Subscribe to Shuyi’s Newsletter to keep reading this post and get 7 days of free access to the full post archives.