从笔记到第二大脑:Flowith 2.0 知识库实测与反思
知识流动本就该如此轻松。不是吗?


痛点
在日常的知识工作中,我一直希望让记录和输出都变得更加简单。简要来说,我的目标是不肯花大功夫整理笔记,却希望获得卡片笔记写作法带来的收益。所以,这些年,你看到了,我没少折腾各种笔记应用。正如我之前所说:
作为一个懒人,我一直希望知识的处理与输出能变得更加容易一些。这些年,我尝试了各种笔记工具,包括 Evernote, Notion, Obsidian, Logseq, Roam Research, Heptabase 等,就是希望能够无压记录,精准回顾,流畅输出。
然而,这些工具对我来说依然不够轻松。在使用 AI 之前,我必须人为地给信息打标签或建立链接,才能后期检索到它们。这种额外负担在实际使用中并没有真正减轻我的工作量。我也曾在文章中表达过自己真切的期待:
…… 随时去记录,而不必操心加工整理的事儿。当我真正想要调用之前的知识储备时,只需要一个自然语言简单查询,AI 就能遍历我的笔记库,自己根据语义找寻相关记录,然后总结输出,给我一个满意的答案。
有了 AI 以后,我也试用多种基于 RAG 技术的工具,例如 Notion AI, Quivr, Elephas, GPTs, Obsidian Copilot, Cursor 等等,却发现它们对懒人仍不够友好。尤其是设置过程复杂,更新不便,对新手来说有门槛。如很多人在配置 Obsidian Copilot 时,会被各种设置问题和不匹配的选项弄得手忙脚乱。
不少工具在用户输入了大量文件后,找寻的准确率和回答的精准度还有很大提升空间,这一点也让 我在使用过程中深有体会。我曾经尝试通过更好的 embedding 模型和排序方法来解决,但这显然不符合「懒人法则」,不够「开箱即用」。
因此,当我得知 Flowith 2.0 增加了知识库功能,而且很多小伙伴试用后反馈效果很好时,便想测试一下它是否能解决我在知识管理和利用上的痛点。我期待通过这种方式,不用再面对繁琐的设置步骤,就能准确提取出相关笔记,并实现更顺畅的创作过程,也希望它能够成为真正意义上的 「第二大脑」。
这篇文章,就是我的实践过程和反思总结,希望对你的知识工作有帮助。
构建
Flowith 这东西,半年多以前,我就给你推荐过。最近它邀请用户参与 2.0 Beta 版本内测,我立即就填写了表格,很快被工作人员拉入群里,且给了 Premium 兑换码。
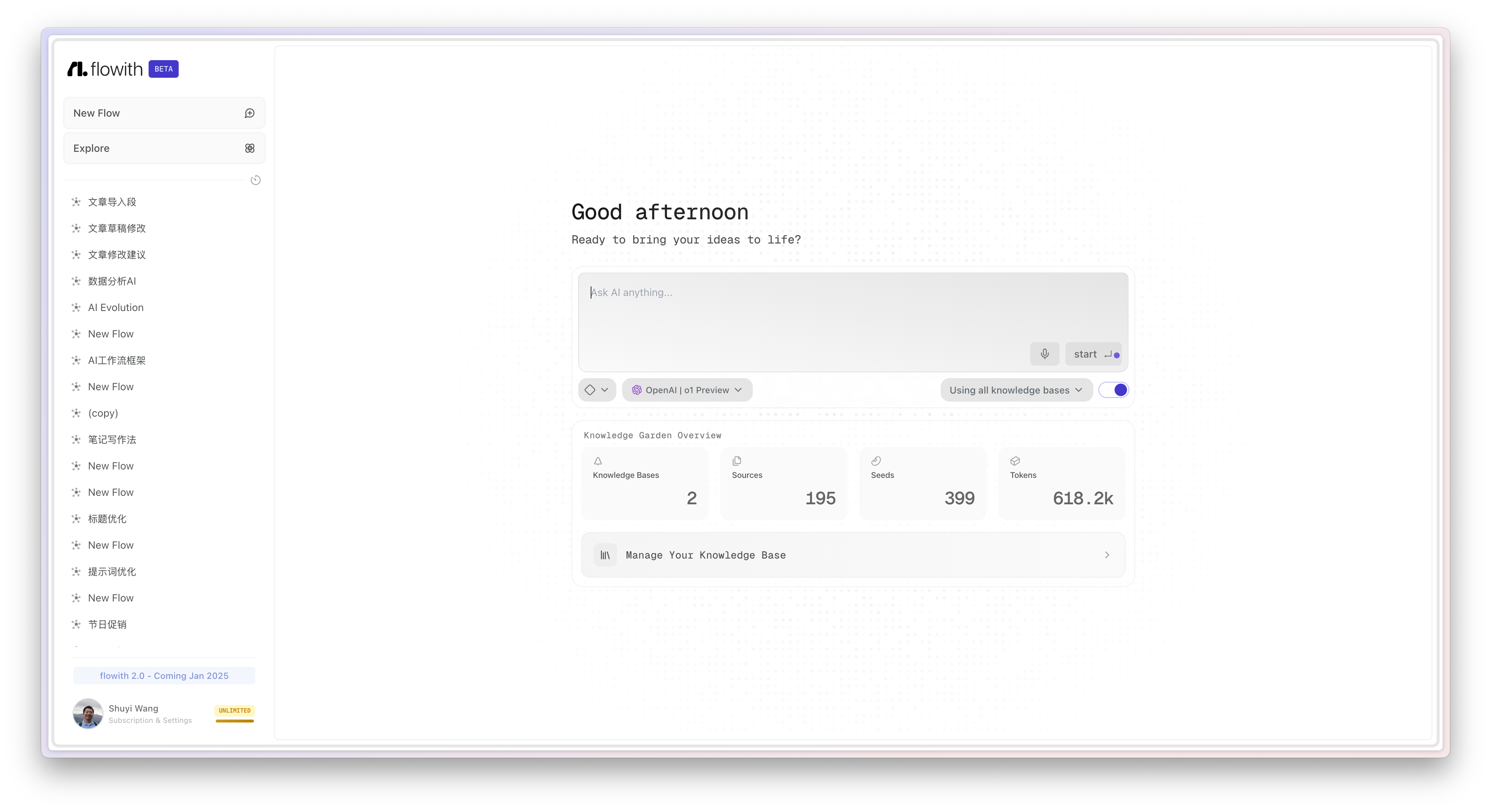
我于是立即开始尝试构建知识库。方法是选择 "Manage Your Knowledge Base",进入知识库管理页面。
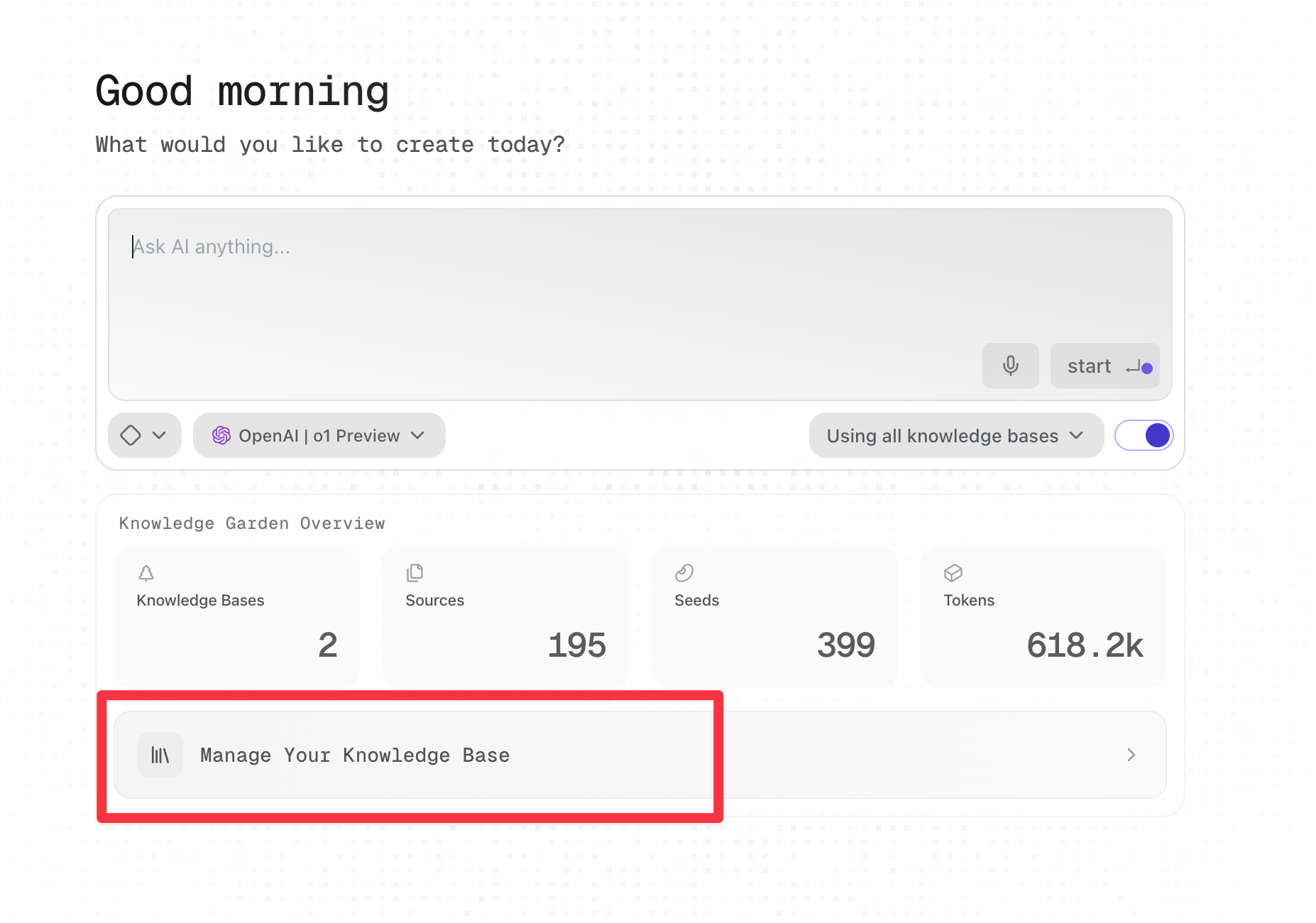
然后选择左上角的加号,添加新的知识库。
你可以随意给知识库起个名。但是我强烈建议你起个自己后来能分辨的名字,不然使用的时候会不方便找寻。

下面,你就可以点击添加文件。
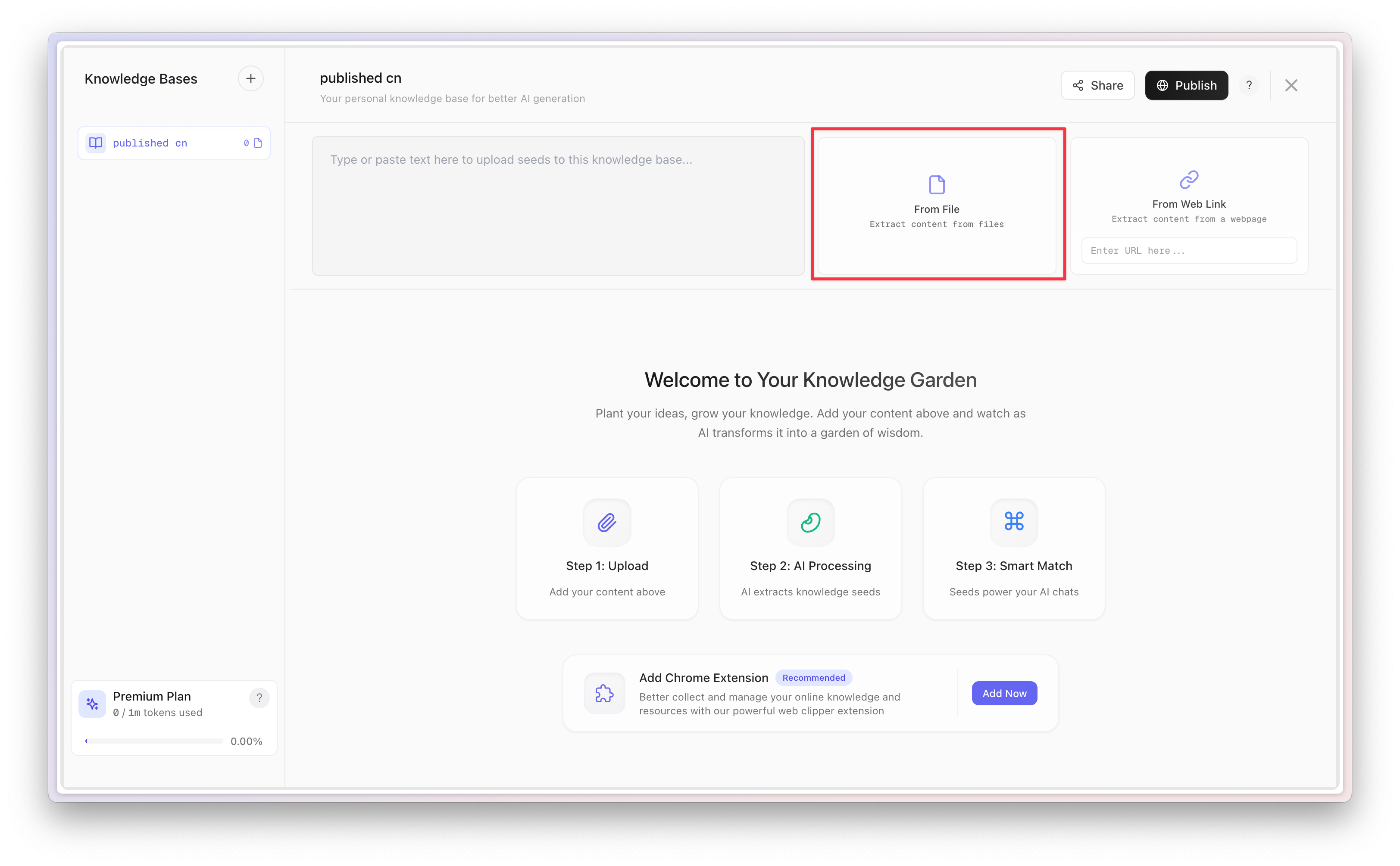
我建议你使用 Markdown 格式的文件。我平时发布的文章,存储的都是这种格式。它其实就是带标记的纯文本,比较符合大语言模型的偏好。
接着,你会看到 Flowith 开始忙活,逐个文件进行抽取(Extraction)等处理。
你根本无需操心它是怎么做的。关上页面,等处理好了再说。
过了一会儿,处理完毕。我点开其中某一个文件看看。处理过后它包含 3 个 seeds,也就是因为长度关系,切分成了 3 个部分。
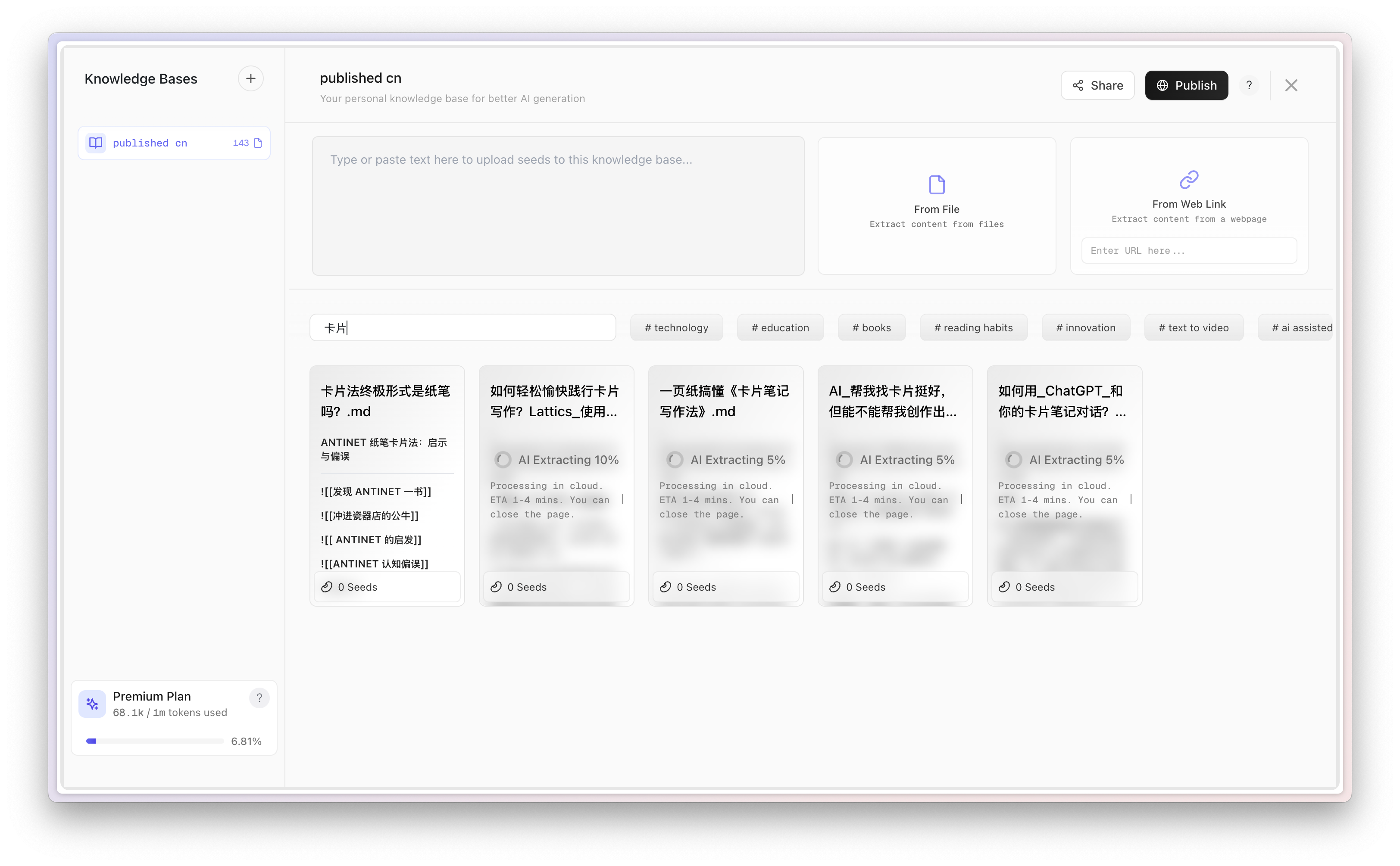
你可以在知识库管理页面测试检索。例如我这里输入「卡片」,就可以过滤出与「卡片」直接相关的发布文章内容。
这就是知识库的构建方法 —— 新建、拖拽、等待、搞定。
按照类似的逻辑,我分别构建了「《玉树芝兰》公众号文章」和「《玉树芝兰》知识星球文章」两个知识库。

知识库构建好了,咱们尝试一下问答吧。
尝试
我们先来尝试一下利用「《玉树芝兰》公众号文章」来回答问题。
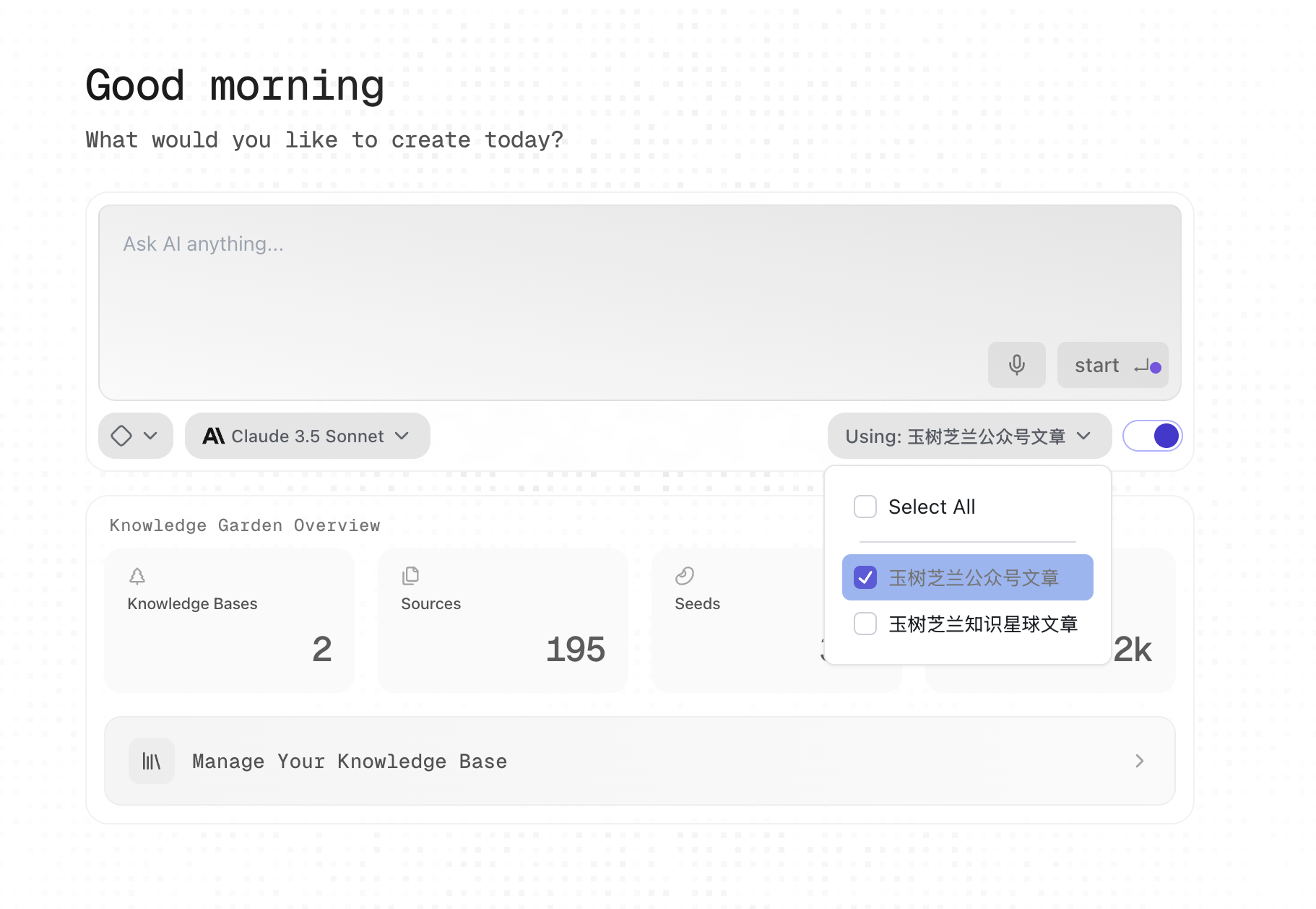
我这里的设定是使用普通模式(其他模式包括绘图、视频制作、在线检索、提示词优化……)。选择用 Claude 3.5 Sonnet 作为大模型,然后注意只选择「《玉树芝兰》公众号文章」这一个知识库。
我提出的问题为:
如何用 AI 辅助数据分析?
这是 Flowith 给出的答案:
Keep reading with a 7-day free trial
Subscribe to Shuyi’s Newsletter to keep reading this post and get 7 days of free access to the full post archives.