文献综述能放心交给 AI 吗?
聊聊如何搭建「不翻车」的科研工作流


疑问
星友「小范老师」是一位经济统计学专业的高校教师,最近在星球提问,问题比较长。
我简单梳理一下,他会 R、Python 和 Stata,平时做计量经济学实证研究,但对编程和命令行不太熟悉。他的目标很明确 —— 想搭建一套能辅助写计量经济学实证论文的 AI 工作流,既提高效率,也通过这个过程学习更好的研究方法。
小范老师问了三个问题:
现在用 AI 查到的文献靠谱吗?我能依赖 AI 来做文献综述吗?
如果我已经有了一个观点,想反向查找高质量文献来支撑,有什么好用的工具?
科研相关的 Claude Code Skill,有没有适合初学者模仿学习的推荐?
今天这篇文章,咱们就来聊聊这几个有趣又有价值的问题。
文献
先来解决第一个问题:
现在用 AI 查到的文献靠谱吗?我能依赖 AI 来做文献综述吗?
先说结论:不能轻信。
你用 ChatGPT 或者 DeepSeek 写过文献综述吗?如果你让它们「推荐几篇关于数字经济对中小企业融资影响的论文」,它们会非常自信地列出一串看起来像模像样的引用 —— 有作者、有标题、有期刊名、有年份。
问题在于,这些引用里很有可能有一部分是编造的。你可以参考我这篇文章,看看这种幻觉可能有多严重。只不过,我当时只是进行测试。后来才发现,学术界早已有很多研究,甚至是「翻车」案例了。
Enago Academy 的一项研究汇总了多个模型的学术文献检索表现,结果触目惊心:AI 生成的参考文献中,仅 26.5% 完全正确,近 40% 是错误的或者干脆捏造的。肾脏病学领域的一项评估更直接点名——ChatGPT 建议的文献中,只有 62% 真实存在,剩下 31% 要么是凭空捏造的,要么是把真实论文的信息张冠李戴拼凑出来的。
你可能会想:这些编造的引用应该很容易识别吧?不一定。 GPTZero 的研究 发现了三种幻觉类型。第一种是「混搭」:把几篇真实论文的作者、标题、期刊名混在一起,拼出一篇不存在的论文 —— 看起来完全可信,因为每个元素都是真的,只是组合是假的。第二种是「完全捏造」:从作者到期刊全是编的。第三种最隐蔽 —— 以一篇真实论文为基础,做微妙修改:把缩写名展开、增删一个作者、改述标题。你若是不去数据库逐字核对,根本发现不了。
有人中招吗?
GPTZero 扫描了 NeurIPS 2025 收录的 4000 多篇论文,发现至少 53 篇包含幻觉引用,总共 100 多条。这些论文每篇都经过 3 位以上审稿人审阅,没有一个人发现引用是编的。 ICLR 2026 的抽样检查 也是类似的结果:300 篇中超过 50 篇包含至少一条幻觉引用,每篇都经过 3 到 5 位审稿人审过。
连 AI 领域最顶级会议的审稿人都发现不了,怎么办?
根本原因在于工作机制。 虽然 ChatGPT(2024 年底)和 Claude(2025 年初)都已经有了联网搜索功能,能在开放网络上找到 arXiv 预印本、PubMed 开放获取论文之类的内容,但它们仍然无法直接查询 JSTOR、Scopus、Web of Science 这些付费学术数据库。更要命的是,即使开着搜索,生成引用时的幻觉问题依然严重——模型可能把搜到的真实信息和训练数据里的模式混在一起,编出一条「看起来特别像真的」的引用。换句话说,它不是纯粹「查」出来的,很大程度上还是在「猜」(或者,说得更直白些,「编」)。这跟你去知网或者 Web of Science 搜索有本质区别。
那是不是 AI 做文献综述就完全不能用了?
不是。 关键在于区分「通用 AI」和「学术专用 AI」两类工具。
ChatGPT 和 Claude 虽然能联网搜索,但它们搜的是开放网络,进不了付费数据库,生成引用时仍然可能会「猜」。但 Elicit、Consensus、Semantic Scholar 这些专用学术搜索工具完全不同 —— 它们直接查询真实的论文数据库(Semantic Scholar 收录超过 2 亿篇论文),返回的每一条结果都有原文可溯源。
以 Elicit 为例,你输入自然语言描述你的研究问题,它从真实论文中检索结果,每条结论都附带句子级引用 —— 不仅告诉你「哪篇论文支持这个观点」,还精确到「论文里哪句话说了这个」。
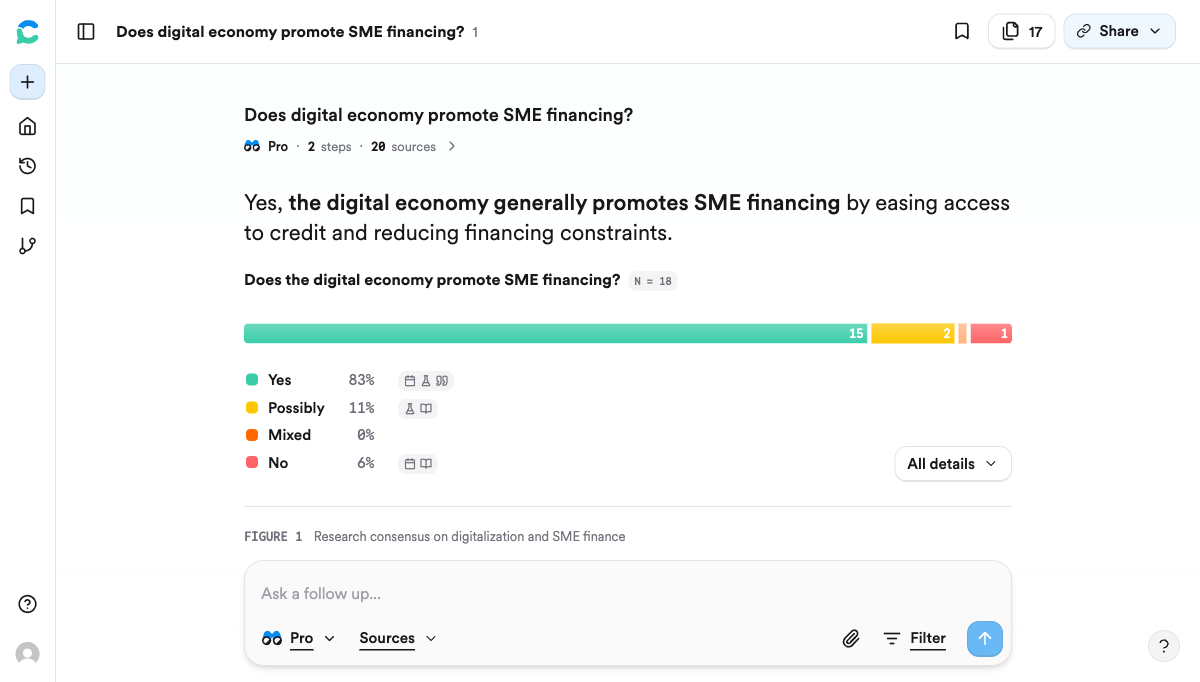
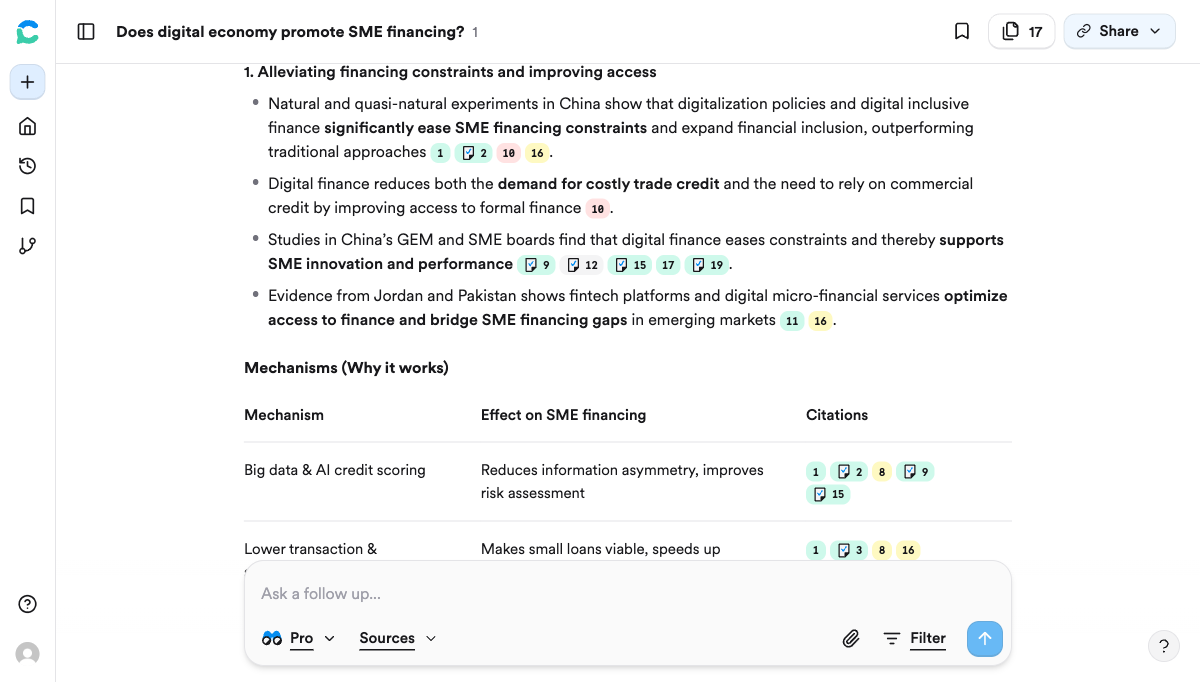
Consensus 的独特之处在于它的 “Consensus Meter”—— 搜索一个学术问题后,直接显示研究者群体对这个问题的共识程度。比如我输入 “Does digital economy promote SME financing?”,它会自动检索相关论文,然后告诉我各类结论占比。你能一眼看出这个论点在学界站不站得住脚。
中文文献也有解决方案。例如知网推出了 CNKI AI 学术研究助手,已经接入了 DeepSeek,提供 AI 增强检索、AI 辅助研读、AI 辅助创作和苹果树智能体四项服务,2025 年起已在多所高校开通试用。需要你通过学校图书馆关联机构账号才能使用。
科睿唯安也给 Web of Science 配了 AI 研究助手。这两个属于「数据库原生 AI」—— 来源可追溯、可靠性通常更高,但依然建议你做人工核对。这些学术数据库提供商自研的 AI 产品嘛,缺点是各自只覆盖自己的库。
只不过,我多句嘴,「准确」和「好用」,不能完全划等号。
还有一类值得关注的中间选项。 Perplexity 在文档里提供了偏学术场景的检索指引(文档路径近期有调整,可从 Overview 进入)。 独立评测 提到,它在复杂研究问题上给出的来源可追溯性优于部分通用模型;但它也有问题:引用有时指向主页而非具体文章,直接引用有时在所引来源中找不到。所以仍需人工核实。
所以回答你的问题:能不能依赖 AI 做文献综述?
不能依赖 ChatGPT、DeepSeek 这类通用 AI。可以更倾向使用 Elicit、Consensus、Semantic Scholar 这类专用学术 AI 工具。后者整体上更容易追溯来源。
我提醒一下,不管你用哪个工具,最后都要回到知网或 WoS 原库做一遍核实。关于这个话题,我之前在 《如何提升 AI 学术检索的质量?》 中也有一些实践总结,若你感兴趣可以看看。
知道了哪些能信、哪些不能信,你或许已经迫不及待想知道:具体怎么操作?特别是你已经有了一个观点 —— 比如「数字普惠金融能降低信息不对称」—— 怎么反向找到高质量文献来支撑它?这正是第二个问题要回答的。
求索
反向文献查找 —— 已经有了观点或论述,反过来找支撑文献 —— 其实有两种完全不同的策略。搞清楚这两种策略的区别,你就知道什么场景该用什么工具了。
第一种叫「以意找文」:你脑子里有一个观点(比如「数字普惠金融能降低信息不对称」),用自然语言描述这个观点,让 AI 去论文库里找支持它的研究。这种策略适合你有想法但手头没有任何相关论文的阶段。
第二种叫「以文找文」:你手头已经有了一篇相关论文,想通过这篇论文的引用网络找到更多相关研究。这种策略适合你已经有了一两篇核心论文,想扩大文献覆盖面的阶段。
最高效的做法是两者结合:先用「以意找文」找到几篇核心论文,再用「以文找文」从这几篇出发展开引用网络。很早之前,我就把这种方式定义为「孔雀开屏」。
来说说每种策略下好用的工具。
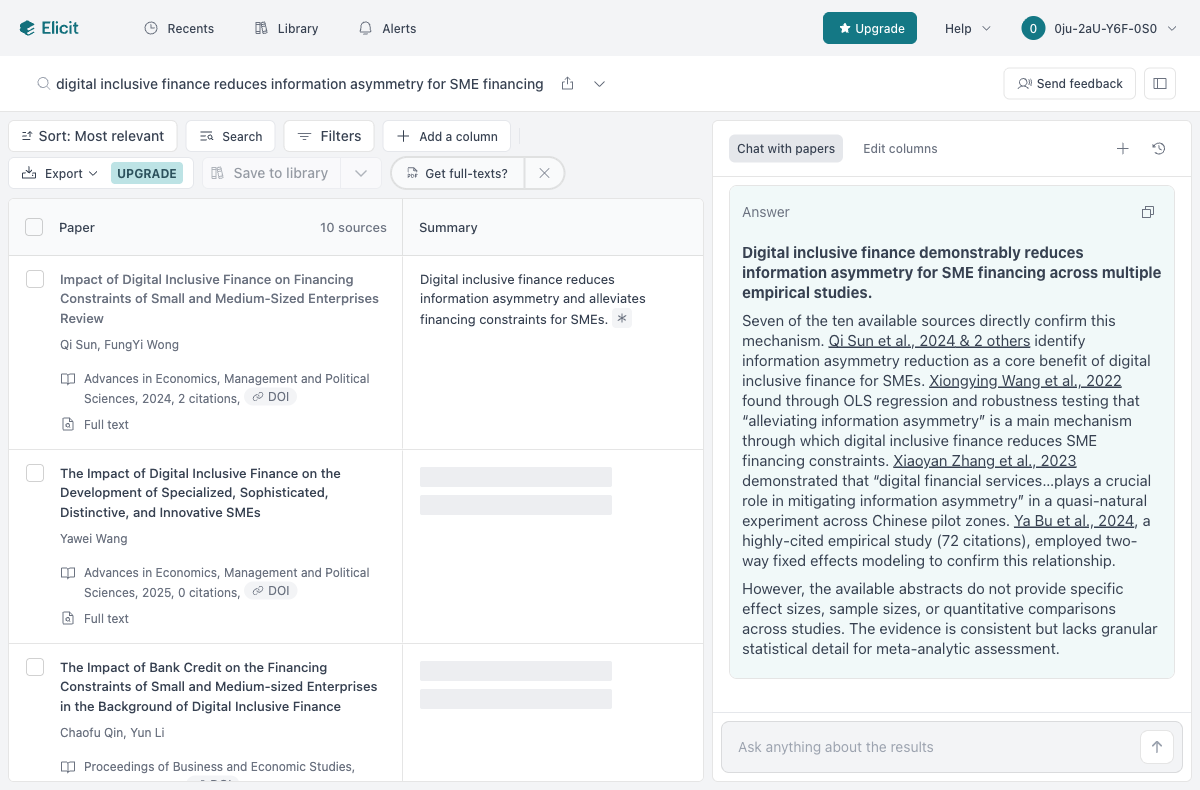
以意找文,首推 Elicit。 你用自然语言描述观点(如 “digital inclusive finance reduces information asymmetry for SME financing”),它可以在大规模论文库中做语义检索并返回相关论文。按 Elicit 官网当前公开信息,它已覆盖 1.25 亿+ 论文。它的优势是句子级证据链:不只告诉你“这篇论文相关”,还会把支持结论的原文句子/表格片段摘出来并链接回来源位置。基础功能有免费版;具体配额和价格更新较快,建议以官网 Pricing 页面为准。
Consensus 前面提到过,它有一个独门功能:共识度量表。 不仅如此,它还会自动生成带引用编号的结构化分析——列出支持结论的具体机制(如大数据信用评分、降低交易成本等),每条论述都标注了来源论文编号,点击即可溯源。这对你判断一个论点是否站得住脚特别有用。它的文献覆盖规模也是亿级。
如果你需要区分「支持还是反对」, scite.ai 是一个很强的选择。 传统的引用分析只知道 A 引用了 B,不知道是赞同还是反驳。scite.ai 的核心价值就在这儿:它把引用标记为 supporting(支持)、contrasting(反对)或 mentioning(提及)。你找到一篇核心论文,scite.ai 可以直接告诉你有多少后续研究支持它的结论、多少反驳了它。对写文献综述来说,这个功能非常实用。并且在 2026 年,scite.ai 还 推出了 MCP,可直接连接 Claude 等工具。
再说以文找文的工具。
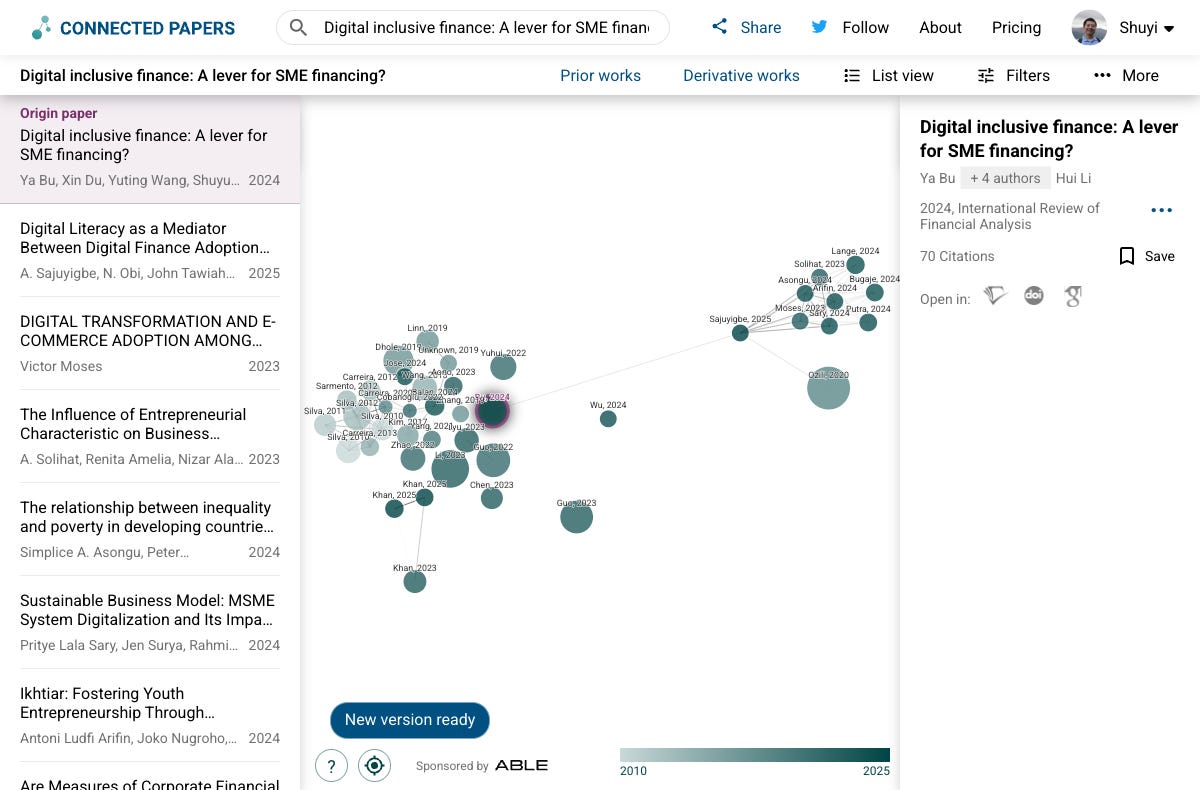
Connected Papers 是我最推荐的引用网络可视化工具。 你提供一篇论文作为「种子」,它会基于文献耦合和共被引分析生成一张可视化的关联论文图谱。注意它不仅仅看直接引用关系,还考虑两篇论文是否被相似的论文群引用——这意味着它能发现那些虽然没有直接引用关系、但研究内容高度相关的论文。在一份 独立评测 中,它被评价为快速简洁的单种子文献发现工具,免费就够用。
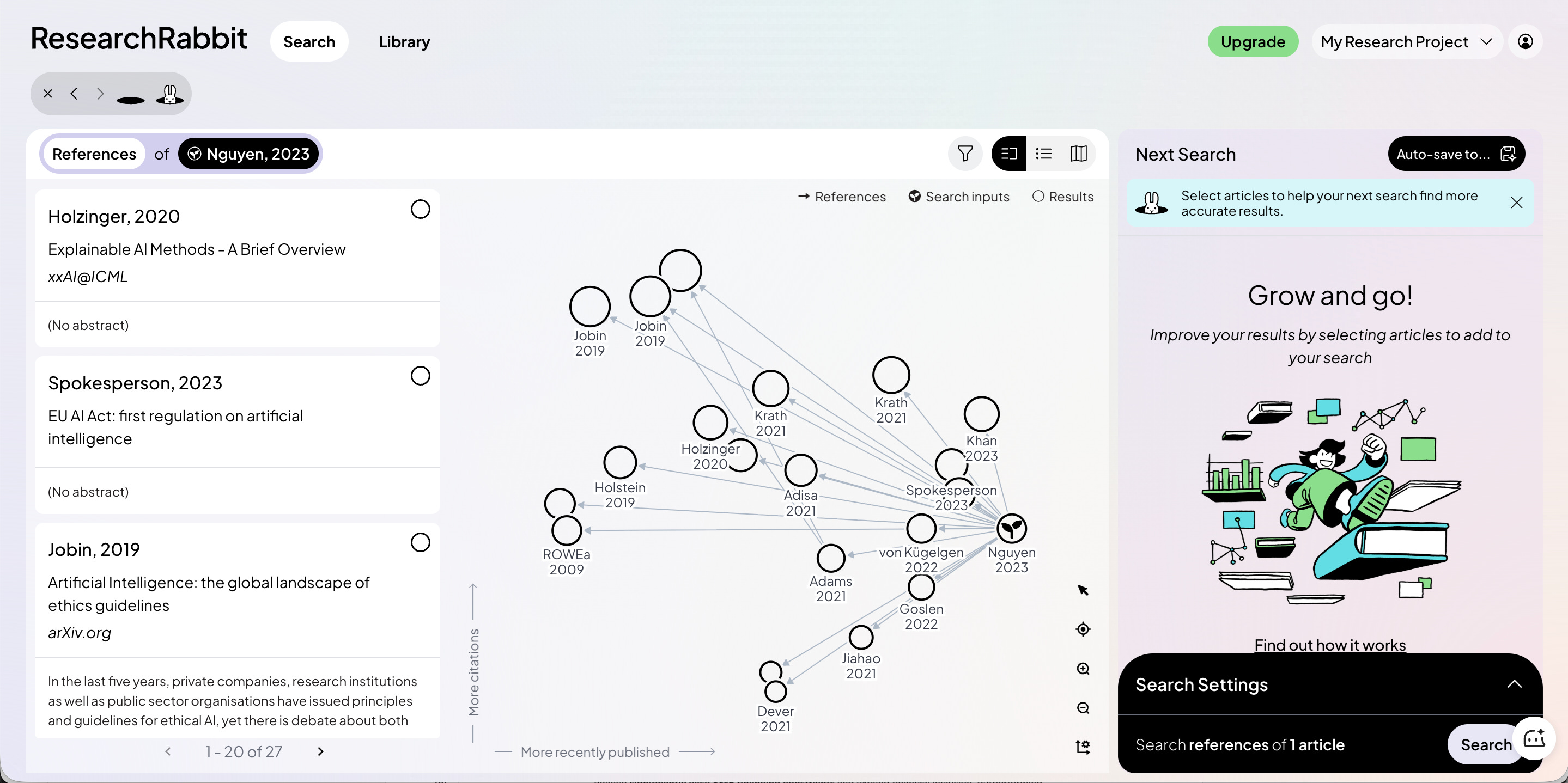
Research Rabbit 的特色是迭代式深挖。 我在好几年前,就用视频给你介绍过它。你搜一轮,它记住结果;在这个基础上再搜一轮,它还记着。每次搜索都保存,随时可以回溯到之前的任何一步。2025 年 10 月它做了一次 重大更新,搜索流程更清晰,引用图可以自己配置。
用它来做「兔子洞式」文献探索特别合适 —— 一层层往下钻,钻到哪算哪,但随时能回来。
中文文献的反向查找是个缺口。 上面这些工具以英文论文为主,中文文献覆盖有限。目前最好的中文方案是 CNKI AI 的增强检索(语义驱动,不只是关键词匹配)加上知网自带的引用追踪功能。
拿你的研究方向来验证一下:假设你想写「数字经济对中小企业融资的影响」。用 Consensus 输入 “Does digital economy promote SME financing?”,几秒钟就拿到结果——前面截图里你已经看到了,83% 的研究给出肯定答案,而且它自动整理出了四大促进机制(大数据信用评分、降低交易成本、替代融资平台、长尾企业覆盖),每条都带着论文编号。这就是你文献综述的骨架。用 CNKI AI 输入中文关键词,得到中文期刊论文。然后你已经有一个观点「数字普惠金融能降低信息不对称」,用 Elicit 搜索,找到支持该观点的实证论文。再从一篇核心论文出发,用 Connected Papers 展开引用网络。最后用 scite.ai 确认引用方向。整个 workflow 走一遍,英文和中文文献都覆盖到了。
技能
你问的第三个问题 —— 有没有适合初学者模仿学习的科研 Skill—— 是三个问题里我最想展开讲的。因为这件事的价值不仅在于「用上一个好工具」,而在于「学会怎么把自己的研究经验变成可复用的 AI 工作流」。
Keep reading with a 7-day free trial
Subscribe to Shuyi’s Newsletter to keep reading this post and get 7 days of free access to the full post archives.