如何用 AI 帮你轻松实现多语种写作?
有时挡住你前进的因素,只是一些「不方便」。


需求
我平时一般都用中文写文章做视频。但是我逐渐发现,读者和观众里面也不乏完全不懂中文的人。
2021 年,我写作一篇介绍 Hookmark (彼时还叫做 Hook) 的文章,链接在这里。
文章写过之后,Hookmark 的作者 Luc P. Beaudoin 干脆就在网上发寻人启事了。
我当时就纳闷儿,外国人都认识中文了吗?其实不是,Luc P. Beaudoin 还专门写了篇文章,说明了阅读过程。原来他用了 Safari 的翻译插件。

外国人读中文,用机器翻译虽然不能保证百分百准确理解。但通过脑补,也能看懂个八九不离十。于是我就琢磨 —— 既然外国人能用自动翻译,那我只需要坚持输出一种文字(中文),然后让外国人自己用翻译插件来看不就完了?
从那儿以后,我单独输出英文版本的文章更少了。不过后来我发现,自己这个假设(外国人都是用翻译插件来读中文文章)根本不靠谱。就连我自己订阅的 RSS ,也经常会干脆忽略其中的英文内容,只看中文篇目。因为你抵挡不了母语熟悉程度的诱惑。他们连你的文章都不会注意到,又怎么会拿插件翻译后费劲地认真看呢?
要想真正把内容交付给更广泛的受众群体,翻译成外文就是不可或缺的过程。
2021 年 6 月份,和 Jamie Miles 那次直播对话之后,我写了个总结帖子。Jamie 读过后,立即要求合作 —— 他翻译到英语,注明内容来自我这边。
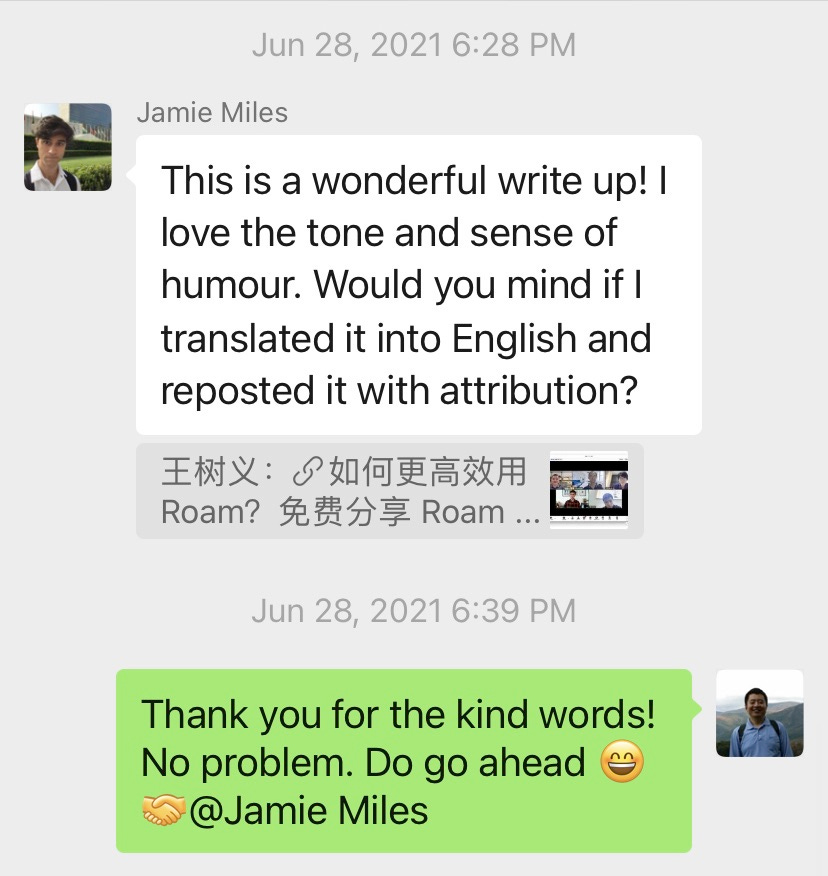
这样做的目的,当然是为了更广泛的传播。
我自己之前也有体会。例如当初在 Medium 的 Towards Data Science 专栏以英文写作的时候,外国人订阅和反馈还真是不少。但是后来我因为工作忙碌,没能继续坚持下来。Medium 上的文章还在写,但全都改成了中文。这下外国读者即便订阅了,也很少再给出反馈了。
与之形成对比的是,最近我又尝试了把几篇中文文章翻译成英文放在 Medium 上,效果立竿见影。文后很快就有了读者给出的积极反馈,英文写的。
你看,翻译成英文,是不是扩大读者范围的重要手段呢?
只不过,如果你真正尝试过就会发现,这可没有看起来那么方便和简单。
困难
把中文文章翻译成英文,最困难的部分在哪里?
原先,自然是在于内容的翻译。我在 Medium 上写 Towards Data Science 专栏文章时,采用的是彼时较为先进的 Google Translate 。翻译的效果很是一般,经常需要大量的后期人工处理,包括纠错、润色等。要不然,真会出现低级错误。后来,我干脆自己直接用英文写,这样起码对于初稿的控制程度大幅提升。
有了 DeepL 之后,我觉得曙光来了,还专门在知识星球上写了一篇文章《如何低成本发布多语种文档?》。文中我为读者介绍了自己用 DeepL 翻译文章,外加 Grammarly 纠错的方式。
但是,你想不到吧?我那次文章写完,之后就很长时间也没有再发布过英文文章。因为我还是觉得这个过程太麻烦了。
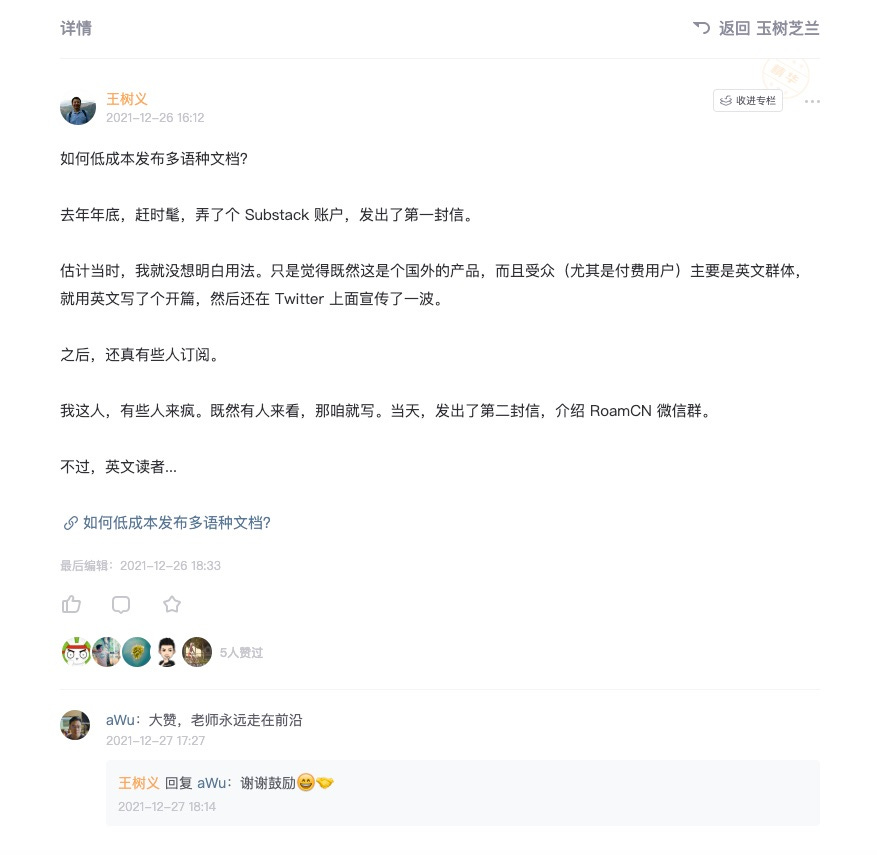
DeepL 翻译,有的时候确实不靠谱,会出现细节上的错误。你必须从头到尾认真校对,才能找出来。例如 这是推友「花果山大圣」做的测试,我觉得很生动,也很有代表性。
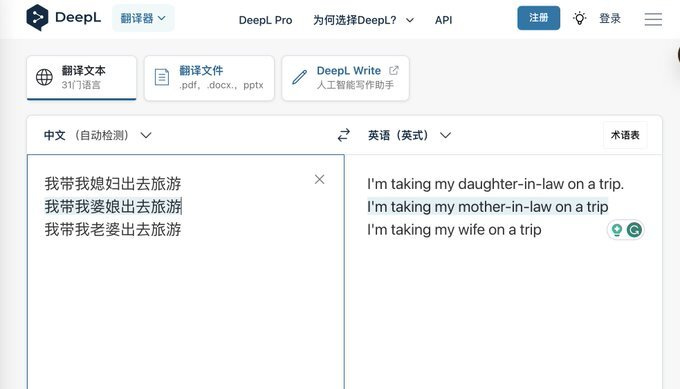
你看同样表达一个意思的 3 句话,被翻译成含义大相径庭的英文。如果你不做仔细校对,那么翻译的结果可能会搞得读者甚至作者自己都啼笑皆非。
DeepL 另外的一个问题,在于特殊格式(例如代码、图片、链接)的处理上,时常出现问题。
对比一下,我之前使用 Google Translate 翻译的时候,它甚至把链接里面的英文也都翻译成中文返回给我,让我哭笑不得。DeepL 在这方面好了一些,至少链接不再强行翻译了,但其他内容依然有问题。
下面咱们以我前些日子发布的公众号文章《如果笔记软件公司倒闭了,你的笔记还能接着用吗?》为例,看看 DeepL 翻译效果。
把它弄成 Markdown 格式,放入 DeepL ,翻译效果如下。
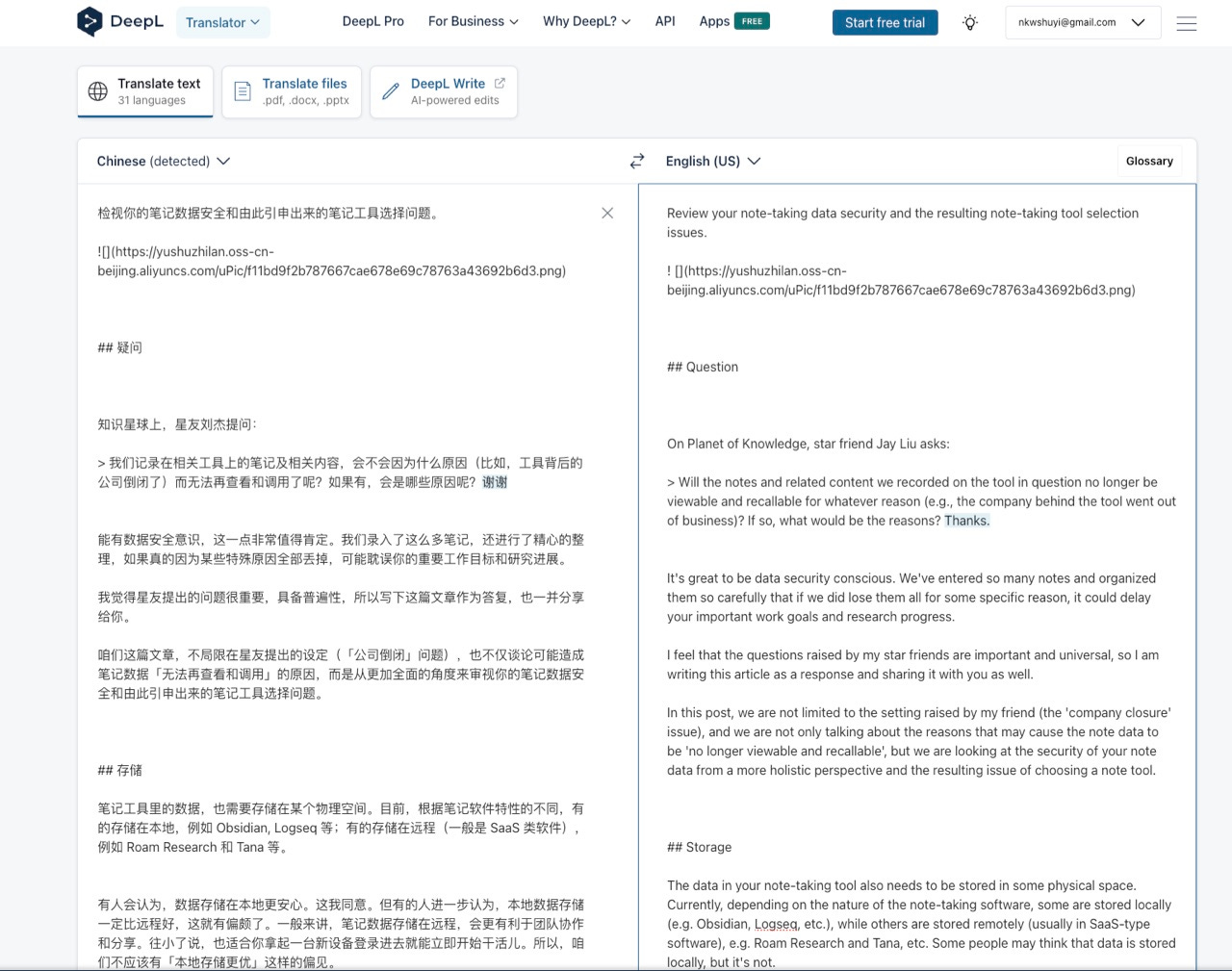
看起来,好像都不错。不过如果你把翻译之后的内容拷贝到 Typora ,结果是这样的:
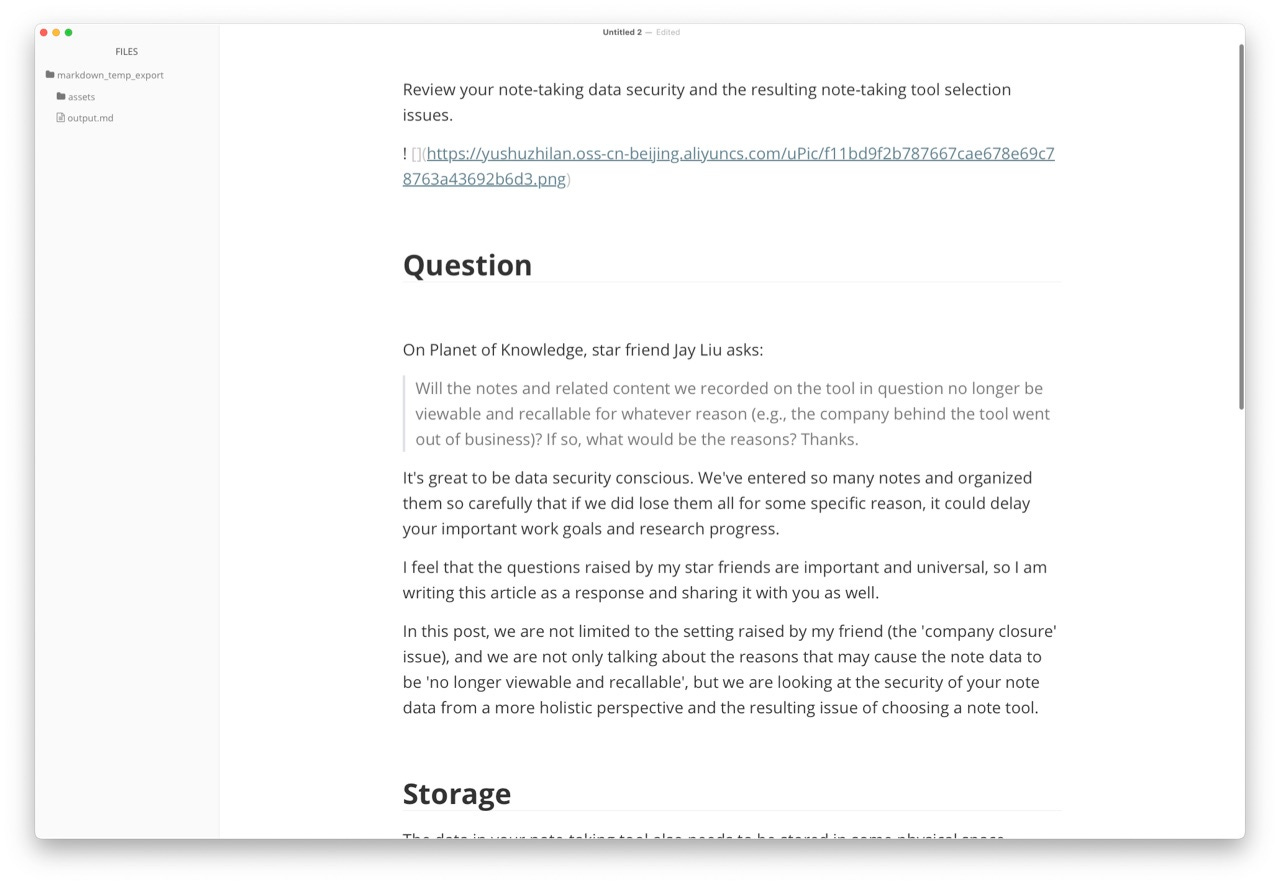
你会清楚地看到,图都无法显示。为什么呢?
因为 DeepL 居然自作主张,在表示图片链接格式的符号 ! 和 [] 之间,给你平白无故加上一个空格。
这只是 DeepL 处理特殊格式出错的一个例子,绝非全部。想想看,若是每次翻译都这么麻烦,得人工校对,还得处理格式细节…… 反正我一动念头便会感到相当头疼。于是,当初雄心勃勃的 DeepL + Grammarly 文章批量翻译计划,由于我选用的技术方案有瑕疵,就这么长期搁置了。
2022 年末,平地一声惊雷,ChatGPT 为代表的 AIGC 来了。
曙光
我测试了 ChatGPT 翻译能力后,立即写下了一篇《我退订了智能翻译工具 DeepL Pro ,其实它真没有做错什么》,从这个标题里,你也能直观看出我的结论。
这之后 GPT-4 的翻译和校对能力,更是让我感到惊艳。它不仅可以翻译内容,还能够利用自己广泛的阅读经历,按照你指定的风格来输出文字。我一直怀疑,AudioPen 所使用的大模型,就是 GPT-4 。
只不过,GPT-4能够接受的输入长度太短了。我的中文文章,一篇大概至少也有3000-4000字,加上里面的链接、图片、代码等等一起输入,GPT-4根本承接不住。因为它的输入+输出只有8K tokens 长度。
当然咱们得说句公道话,后来 GPT-4 也提供了 32K 的选项,不过 API 调用价格确实贵了一些,而官方 Plus 对话版本又长期不支持这么长的 token 数量。退一步讲,即便有了 32K 的 token 长度,对于长文来说,我实际测试也不是很够用。
好在为咱们提供服务的 LLM (大语言模型)们早已「卷」了起来。你看,Claude 2 直接提供了 100K tokens 的单次对话长度,让用户们惊呼过瘾。
我当时就立即尝试了 Claude 2 的翻译功能。它翻译普通文本真的是效果出众。只不过一旦涉及图文并茂的内容,Claude 就出问题了。
还是以刚才那篇文章为例。
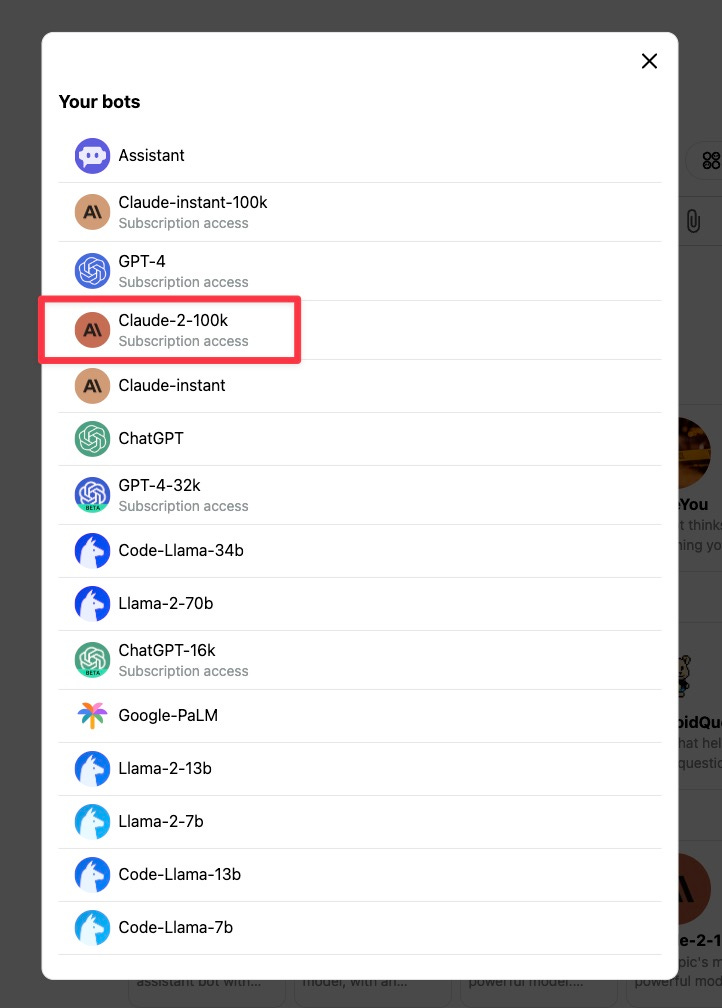
我是用的软件是 PoE ,里面涵盖的大语言模型还真不少。PoE 跟 ChatGPT Plus 比起来各有千秋。PoE 的模型数量可观,ChatGPT Plus 的数据分析与插件系统出众。此处咱们选择 Claude-2-100k 。
然后,我把提示词和文章的 Markdown 文本输入。

回车之后,Claude 2 开始执行。
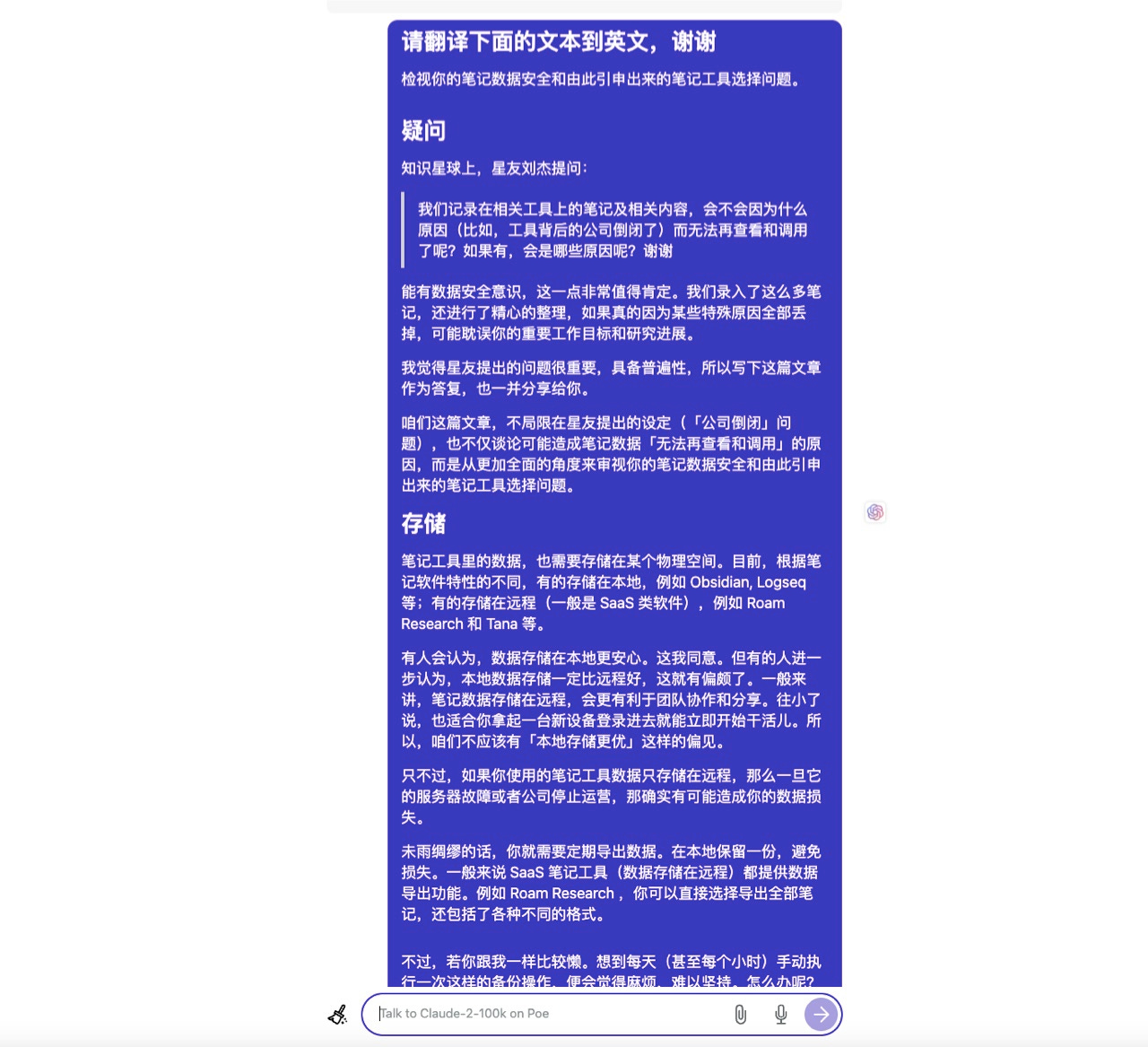
你立即就发现问题了吧?
对,咱就别惦记着翻译结果里面图片链接是否正常了。打从你输入,这些图片就都从文章里消失了。
曙光乍现,就消失了。这让人情何以堪啊?
好在,解法还是有的。
Keep reading with a 7-day free trial
Subscribe to Shuyi’s Newsletter to keep reading this post and get 7 days of free access to the full post archives.