如何用最简方法,爬取网站数据?
小巧、简单、高效、实用。


许多学科的研究工作范式早已是数据驱动。在过去的几年时间里,我给你介绍过不少获取数据的方法。开放数据获取和 API 数据读取更为简单一些,相对而言爬虫就有些复杂。所以我详细介绍使用编程从头做爬虫的教程并不多,而更希望给你介绍一些更为简便的方式,例如这篇。
自从有了大语言模型,我们都看到了一个更加智能时代的来临。我也给你介绍过利用 Code Interpreter 等方式替你编程采集数据的方法,这样你就不用自己手动写代码来抓取数据了。

最近给你介绍的样例是一个定制化的 GPT,是有人专门做好放在 GPTS Store 里面供大家使用的。在这篇文章里,我给你演示了用它来采集我们系的教师介绍网页。

从这个样例中你不难看出,AI Agent 具有很大的潜力,可以为普通用户赋能,帮助你完成从前无法做到的数据采集任务。
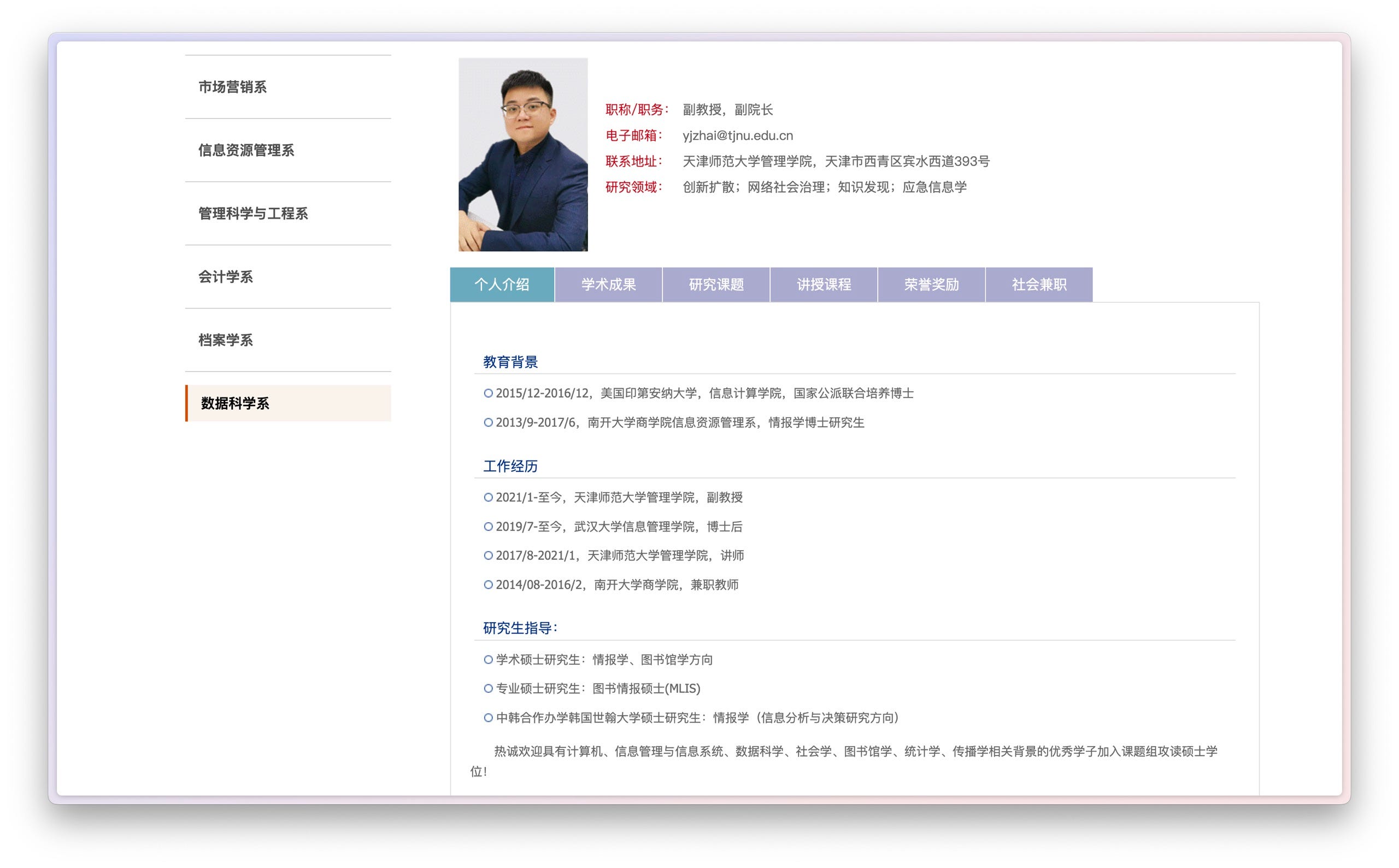
但是它的局限也是非常明显的。例如,我当时希望它采集翟羽佳老师的相关信息,但实际操作中它只抓取了教育背景等基本信息介绍,对于其他分栏下面的信息就没有能够采集出来。这不得不说是一个遗憾,限制了 GPTs 这种数据爬取方式的应用场景。

好在最近我找到了一种更加简便的爬取网页内容的方法,其简便程度真的让我感到有些惊讶。
本文我就把这种方法介绍给你,咱们还是先从爬取翟羽佳老师个人信息这个样例开始吧。
Keep reading with a 7-day free trial
Subscribe to Shuyi’s Newsletter to keep reading this post and get 7 days of free access to the full post archives.